

God created man in his own image.
Man created AI in his own image.
Once again, with footnotes.
God created man in his1 own image.2
Man3 created AI in his3 own image.
At least that is how it started out. But figuring out what our selves are, as machines, is a really difficult task.
We may be stuck in some weird Gödel-like incompleteness world–perhaps we are creatures below some threshold of intelligence which stops us from ever understanding or building an artificial intelligence at our level. I think most people would agree that that is true of all non-humans on planet Earth–we would be extraordinarily surprised to see a robot dolphin emerge from the ocean, one that had been completely designed and constructed by living dolphins. Like dolphins, and gorillas, and bonobos, we humans may be below the threshold as I discussed under “Hubris and Humility”.
Or, perhaps, as I tend to believe, it is just really hard, and will take a hundred years, or more, of concerted effort to get there. We still make new discoveries in chemistry, and people have tried to understand that, and turn it from a science into engineering, for thousands of years. Human level intelligence may be just as, or even more, challenging.
In my most recent blog post on the origins of Artificial Intelligence, I talked about how all the founders of AI, and most researchers since have really been motivated by producing human level intelligence. Recently a few different and small groups have tried to differentiate themselves by claiming that they alone (each of the different groups…) are interested in producing human level intelligence, and beyond, and have each adopted the name Artificial General Intelligence (AGI) to distinguish themselves from mainstream AI research. But mostly they talk about how great it is going to be, and how terrible it is going to be, and very often both messages at the same time coming out of just one mouth, once AGI is achieved. And really none of these groups have any idea how to get there. They are too much in love with the tingly feelings thinking about it to waste time actually doing it.
Others, who don’t necessarily claim to be AI researchers but merely claim to know all about AI and how it is proceeding (ahem…), talk about the exquisite dangers of what they call Super Intelligence, AI that is beyond human level. They claim it is coming any minute now, especially since as soon as we get AGI, or human level intelligence, it will be able to take over from us, using vast cloud computational resources, and accelerate the development of AI even further. Thus there will be a runaway development of Super Intelligence. Under the logic of these hype-notists this super intelligence will naturally be way beyond our capabilities, though I do not know whether they believe it will supersede God… In any case, they claim it will be dangerous, of course, and won’t care about us (humans) and our way of life, and will likely destroy us all. I guess they think a Super Intelligence is some sort of immigrant. But these heralds who have volunteered their clairvoyant services to us also have no idea about how AGI or Super Intelligence will be built. They just know that it is going to happen soon, if not already. And they do know, with all their hearts, that it is going to be bad. Really bad.
It does not help the lay perception at all that some companies claiming to have systems based on Artificial Intelligence are often using humans to handle the hard cases for their online systems, unbeknownst to the users. This can seriously confuse public perception of just where today’s Artificial Intelligence stands, not to mention the inherent lack of privacy since I think we humans are somehow more willing sometimes to share private thoughts and deeds with our machines than we are with other people.
In the interest of getting to the bottom of all this, I have been thinking about what research we need to do, what problems we need to solve, and how close we are to solving all of them in order to get to Artificial General Intelligence entities, or human intelligence level entities. We have been actively trying for 62 years, but apparently it is only just right now that we are about to make all the breakthroughs that will be necessary. That is what this blog is about, giving my best guess at all the things we still don’t know, that will be necessary to know for us to build AGI agents, and then how they will take us on to Super Intelligence. And thus the title of this post: Steps Toward Super Intelligence.
And yes, this title is an homage to Marvin Minsky’s Steps Toward Artificial Intelligence from 1961. I briefly reviewed that paper back in 1991 in my paper Intelligence Without Reason, where I pointed out the five main areas he identifies for research into Artificial Intelligence were search, three ways to control search (for pattern-recognition, learning, and planning), and a fifth topic, induction. Pattern recognition and learning have today clearly moved beyond search. Perhaps my prescriptions for research towards Super Intelligence will also turn out to be wrong before very long. But I am pretty confident that the things that will date my predictions are not yet known by most researchers, and certainly are not the hot topics of today.
This started out as a single long essay, but it got longer and longer. So I split it into four parts, but they are also all long. In any case, it is the penultimate essay in my series on the Future of Robotics and Artificial Intelligence.
BUT SURELY WE (YES, US HUMANS!) CAN DO IT SOON!
Earlier I said this endeavor may take a hundred years? For techno enthusiasts, of which I count myself as one, that sounds like a long time. Really, is it going to take us that long? Well, perhaps not, perhaps it is really going to take us two hundred, or five hundred. Or more.
Einstein predicted gravitational waves in 1916. It took ninety nine years of people looking before we first saw them in 2015. Rainer Weiss, who won the Nobel prize for it, sketched out the successful method after fifty one years in 1967. And by then the key technologies needed, laser and computers, were in wide spread commercial use. It just took a long time.
Controlled nuclear fusion has been forty years away for well over sixty years now.
Chemistry took millennia, despite the economic incentive of turning lead into gold (and it turns out we still can’t do that in any meaningful way).
P=NP? has been around in its current form for forty seven years and its solution would guarantee whoever did it to be feted as the greatest computer scientist in a generation, at least. No one in theoretical computer science is willing to guess when we might figure that one out. And it doesn’t require any engineering or production. Just thinking.
Some things just take a long time, and require lots of new technology, lots of time for ideas to ferment, and lots of Einstein and Weiss level contributors along the way.
I suspect that human level AI falls into this class. But that it is much more complex than detecting gravity waves, controlled fusion, or even chemistry, and that it will take hundreds of years.
Being filled with hubris about how tech (and the Valley) can do whatever they put their mind to may just not be nearly enough.
Four Previous Attempts at General AI
Referring again to my blog post of April on the origins of Artificial Intelligence people have been actively working on a subject, explicitly called “Artificial Intelligence” since the summer of 1956. There were precursor efforts for the previous twenty years, but that name had not yet been invented or assigned–and once again I point to my 1991 paper Intelligence Without Reason for a history of the prior work and the first 35 years of Artificial Intelligence.
I count at least four major approaches to Artificial Intelligence over the last sixty two years. There may well be others that some would want to include.
As I see it, the four main approaches have been, along with approximate start dates:
- Symbolic (1956)
- Neural networks (1954, 1960, 1969, 1986, 2006, …)
- Traditional robotics (1968)
- Behavior-based robotics (1985)
Before explaining the strengths and weakness of these four main approaches I will justify the dates that I given above.
For Symbolic I am using the 1956 date of the famous Dartmouth workshop on Artificial Intelligence
Neural networks have been investigated, abandoned, and taken up again and again. Marvin Minsky submitted his Ph.D. thesis in Princeton in 1954, titled Theory of Neural-Analog Reinforcement Systems and its Application to the Brain-Model Problem; two years later Minsky had abandoned this approach and was a leader in the symbolic approach at Dartmouth. Dead. In 1960 Frank Rosenblatt published results from his hardware Mark I Perceptron, a simple model of a single neuron, and tried to formalize what it was learning. In 1969 Marvin Minsky and Seymour Papert published a book, Perceptrons, analyzing what a single perceptron could and could not learn. This effectively killed the field for many years. Dead, again. After years of preliminary work by many different researchers, in 1986 David Rumelhart, Geoffrey Hinton, and Ronald Williams published a paper Learning Representations by Back-Propagating Errors, which re-established the field using a small number of layers of neuron models, each much like the Perceptron model. There was a great flurry of activity for the next decade until most researchers once again abandoned neural networks. Dead, again. Researchers here and there continued to work on neural networks, experimenting with more and more layers, and coining the term deep for those many more layers. They were unwieldy and hard to make learn well, and then in 2006 Geoffrey Hinton (again!) and Ruslan Salakhutdinov, published Reducing the Dimensionality of Data with Neural Networks, where an idea called clamping allowed the layers to be trained incrementally. This made neural networks undead once again, and in the last handful of years this deep learning approach has exploded into practicality of machine learning. Many people today know Artificial Intelligence only from this one technical innovation.
I trace Traditional Robotics, as an approach to Artificial Intelligence, to the work of Donald Pieper, The Kinematics of Manipulators Under Computer Control, at the Stanford Artificial Intelligence Laboratory (SAIL) in 1968. In 1977 I joined what had by then become the “Hand-Eye” group at SAIL, working on the “eye” part of the problem for my PhD.
As for Behavior-based robotics, I track this to my own paper, A Robust Layered Control System for a Mobile Robot, which was written in 1985, but appeared in a journal in 19864, when it was called the Subsumption Architecture. This later became the behavior-based approach, and eventually through technical innovations by others morphed into behavior trees. I am perhaps lacking a little humility in claiming this as one of the four approaches to AI. On the other hand it has lead to more than 20 million robots in people’s homes, numerically more robots by far than any other robots ever built, and behavior trees are now underneath the hood of two thirds of the world’s video games, and many physical robots from UAVs to robots in factories. So it has at least been a commercial success.
Now I attempt to give some cartoon level descriptions of these four approaches to Artificial Intelligence. I know that anyone who really knows Artificial Intelligence will feel that these descriptions are grossly inadequate. And they are. The point here is to give just a flavor for the approaches. These descriptions are not meant to be exhaustive in showing all the sub approaches, nor all the main milestones and realizations that have been made in each approach by thousands of contributors. That would require a book length treatment. And a very thick book at that. These descriptions are meant to give just a flavor.
Now to the four types of AI. Note that for the first two, there has usually been a human involved somewhere in the overall usage pattern. This puts a second intelligent agent into the system and that agent often handles ambiguity and error recovery. Often, then, these sorts of AI systems have had to deliver much less reliability than autonomous systems will demand in the future.
1. Symbolic Artificial Intelligence
The key concept in this approach is one of symbols. In the straightforward (every approach to anything usually gets more complicated over a period of decades) symbolic approach to Artificial Intelligence a symbol is an atomic item which only has meaning from its relationship to other meanings. To make it easier to understand the symbols are often represented by a string of characters which correspond to a word (in English perhaps), such as cat or animal. Then knowledge about the world can be encoded in relationships, such as instance of and is.
Usually the whole system would work just as well, and consistently if the words were replaced by, say g0537 and g0028. We will come back to that.
Meanwhile, here is some encoded knowledge:
- Every instance of a cat is an instance of a mammal.
- Fluffy is an instance of a cat.
- Now we can conclude that Fluffy is an instance of a mammal.
- Every instance of a mammal is an instance of an animal.
- Now we can conclude that every instance of a cat is an instance of an animal.
- Every instance of an animal can carry out the action of walking.
- Unless that instance of animal is in the state of being dead.
- Every instance of an animal is either in the state of being alive or in the state of being dead — unless the time of now is before the time of (that instance of animal carrying out the action of birth).
While what we see here makes a lot of sense to us, we must remember that as far as an AI program that uses this sort of reasoning is concerned, it might as well have been:
- Every instance of a g0537 is an instance of a g0083.
- g2536 is an instance of a g0537.
- Now we can conclude that g2536 is an instance of a g0083.
- Every instance of a g0083 is an instance of an g0028.
- Now we can conclude that every instance of a g0537 is an instance of an g0028.
- Every instance of an g0028 can carry out the action of g0154.
- Unless that instance of g0028 is in the state of being g0253.
- Every instance of an g0028 is either in the state of being g0252 or in the state of being g0253 — unless the value(the-computer-clock) < time of (that instance of g0028 carrying out the action of g0161).
In fact it is worse than this. Above the relationships are still described by English words. For an AI program that uses this sort of reasoning is concerned, it might as well have been.
- For every x where r0002(x, g0537) then r0002(x, g0083).
- r0002(g2536, g0537).
- Now we can conclude that r0002(g2536, g0083).
- For every x where r0002(x, g0083) then r0002(x, g0028).
- Now we can conclude that for every x where r0002(x, g0537) then r0002(x, g0028).
- For every x where r0002(x, g0028) then r0005(x, g0154).
- Unless r0007(x, g0253).
- For every x where r0002(x, g0028) then either r0007(x, g0252) or r0007(x, g2053) — unless the value(the-computer-clock) < p0043(a0027(g0028, g0161)).
Here the relationships like “is an instance of” have been replaced by anonymous symbols like r0002, and the symbol < replaces “before“, etc. This is what it looks like inside an AI program, but even with this the AI program never looks at the names of the symbols, rather just when one symbol in an inference or statement is the same symbol as in another inference or statement. The names are only there for humans to interpret, so when g0537 and g0083 were cat and mammal, a human looking at the program5 or its input or ouput could put an interpretation on what the symbols might “mean”.
And this is the critical problem with symbolic Artificial Intelligence, how the symbols that it uses are grounded in the real world. This requires some sort of perception of the real world, some way to and from symbols that connects them to things and events in the real world.
For many applications it is the humans using the system that do the grounding. When we type in a query to a search engine it is we who choose the symbols to make our way into what the AI system knows about the world. It does some reasoning and inference, and then produces for us a list of Web pages that it has deduced match what we are looking for (without actually having any idea that we are something that corresponds to the symbol person that it has in its database). Then it is us who looks at the summaries that it has produced of the pages and clicks on the most promising one or two pages, and then we come up with some new or refined symbols for a new search if it was not what we wanted. We, the humans, are the symbol grounders for the AI system. One might argue that all the intelligence is really in our heads, and that really all the AI powered search engine provides us with is a fancy index and a fancy way to use it.
To drive home this point consider the following thought experiment.
Imagine you are a non Korean speaker, and that the AI program you are interacting with has all its input and output in Korean. Those symbols would not be much help. But suppose you had a Korean dictionary, with the definitions of Korean words written in Korean. Fortunately modern Korean has a finite alphabet and spaces between words (though the rules are slightly different from those of English text), so it will be possible to extract “symbols” from looking at the program output. And then you could look them up in the dictionary, and perhaps eventually infer Korean grammar.
Now it is just possible that you could use your extensive understanding of the human world, about which the Korean dictionary must be referring to for many entries, to guess at some of the meanings of the symbols. But if you were a Heptapod from the movie Arrival and it was before (uh-oh…) Heptapods had ever visited Earth then you would not even have this avenue for grounding these entirely alien symbols.
So it really is the knowledge in people’s heads that does the grounding in many situations. In order to get the knowledge into an AI program it needs to be able to relate the symbols to something outside its self consistent Korean dictionary (so to speak). Some hold out hope that our next character in the pantheon of pretenders to the throne of general Artificial Intelligence, neural networks, will play that role. Of course, people have been working on making that so for decades. We’re still a long way off.
To see the richness of sixty plus years of symbolic Artificial Intelligence work I recommend the AI Magazine, the quarterly publication of the Association for the Advancement of Artificial Intelligence. It is behind a paywall, but even without joining the association you can see the tables of contents of all the issues and that will give a flavor of the variety of work that goes on in symbolic AI. And occasionally there will also be an article there about neural networks, and other related types of machine learning.
2.0, 2.1. 2.2, 2.3, 2.4, … Neural networks
These are loosely, very loosely, based on a circa 1948 understanding of neurons in the brain. That is to say they do not bear very much resemblance at all to our current understand of the brain, but that does not stop the press talking about this approach as being inspired by biology. Be that as it may.
Here I am going to talk about just one particular kind of artificial neural network and how it is trained, namely a feed forward layered network under supervised learning. There are many variations, but this example gives an essential flavor.
The key element is an artificial neuron that has n inputs, flowing along which come n numbers, all between zero and one, namely x1, x2, … xn. Each of these is multiplied by a weight, w1, w2, … wn, and the results are summed, as illustrated in this diagram from Wikimedia Commons.
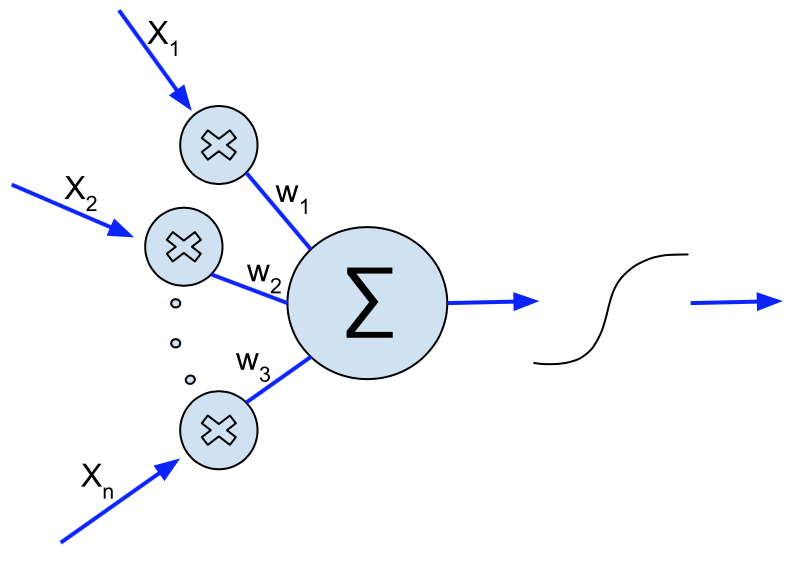
(And yes, that w3 in the diagram should really be wn.) These weights can have any value (though are practically limited to what numbers can be represented in the computer language in which the system is programmed) and are what get changed when the system learns (and recall that learn is a suitcase word as explained in my seven deadly sins post). We will return to this in just a few paragraphs.
The sum can be any sized number, but a second step compresses it down to a number between zero and one again by feeding it though a logistic or sigmoid function, a common one being:

I.e., the sum gets fed in as the argument to the function and the expression on the right is evaluated to produce a number that is strictly between zero and one, closer and closer to those extremes as the input gets extremely negative or extremely positive. Note that this function preserves the order between possible inputs  fed to it. I.e., if
fed to it. I.e., if  then
then  . Furthermore the function is symmetric about an input of zero, and an output of
. Furthermore the function is symmetric about an input of zero, and an output of  .
.
This particular function is very often used as it has the property that it is easy to compute its derivate for any given output value without having to invert the function to find the input value. In particular, if you work through the normal rules for derivatives and use algebraic simplification you can show that

This turns out to be very useful for the ways these artificial neurons started to be used in the 1980’s resurgence. They get linked together in regular larger networks such as the one below, where each large circle corresponds to one of the artificial neurons above. The outputs on the right are usually labelled with symbols, for instance cat, or car. The smaller circles on the left correspond to inputs to the network which come from some data source.
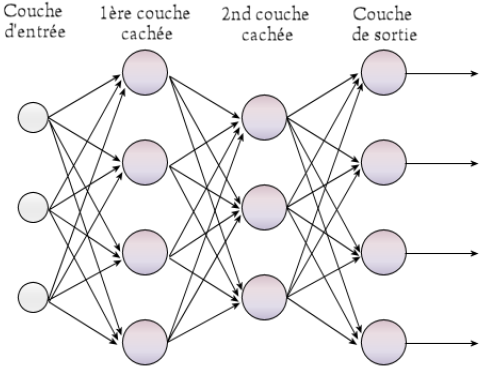
For instance, the source might be an image, there might be many thousand little patches of the image sampled on the left, perhaps with a little bit or processing of the local pixels to pick out local features in the image, such as corners, or bright spots. Once the network has been trained, the output labelled cat should put out a value close to one when there is a cat in the image and close to zero if there is no cat in the image, and the one labelled car should have a value similarly saying whether there is a car in the image. One can think of these numbers as the network saying what probability it assigned to there being a cat, a car, etc. This sort of network thus classifies its input into a finite number of output classes.
But how does the network get trained? Typically one would show it millions of images (yes, millions), for which there was ground truth known about which images contained what objects. When the output lines with their symbols did not get the correct result, the weights on the inputs of the offending output neuron would be adjusted up or down in order to next time produce a better result. The amount to update those weights depends on how much difference a change in weight can make to the output. Knowing the derivative of where on the sigmoid function the output is coming from is thus critical. During training the proportional amount, or gain, of how much the weights are modified is reduced over time. And a 1980’s invention allowed the detected error at the output to be propagated backward through multiple layers of the network, usually just two or three layers at that time, so that the whole system could learn something from a single bad classification. This technique is known as back propagation.
One immediately sees that the most recent image will have a big impact on the weights, so it is necessary to show the network all the other images again, and gradually decrease how much weights are changed over time. Typically each image is shown to the network thousands, or even hundreds of thousands of times, interspersed amongst millions of other images also each being shown to the network hundreds of thousands of times.
That this sort of training works as well as it does is really a little fantastical. But it does work in many cases. Note that a human designs how many layers there are in the network, for each layer how the connections to the next layer of the network are arranged, and what the the inputs are for the network. And then the network is trained, using a schedule of what to show it when, and how to adjust the gains on the learning over time as chosen by the human designer. And if after lots of training the network has not learned well, the human may adjust the way the network is organized, and try again.
This process has been likened to alchemy, in contrast to the science of chemistry. Today’s alchemists who are good at it can command six or even seven figure salaries.
In the 1980’s when back propagation was first developed and multi-layered networks were first used, it was only practical from both a computational and algorithmic point of view to use two or three layers. Thirty years later the Deep Learning revolution of 2006 included algorithmic improvements, new incremental training techniques, of course lots more computer power, and enormous sets of training data harvested from the fifteen year old World Wide Web. Soon there were practical networks of twelve layers–that is where the word deep comes in–it refers to lots of layers in the network, and certainly not “deep introspection”…
Over the more than a decade since 2006 lots of practical systems have been built.
The biggest practical impact for most people recently, and likely over the next couple of decades is the impact on speech transliteration systems. In the last five years we have moved from speech systems over the phone that felt like “press or say `two’ for frustration”, to continuous speech transliteration of voice messages, and home appliances, starting with the Amazon Echo and Google Home, but now extending to our TV remotes, and more and more appliances built on top of the speech recognition cloud services of the large companies.
Getting the right words that people are saying depends on two capabilities. The first is detecting the phonemes, the sub pieces of words, with very different phonemes for different languages, and then partitioning a stream of those phonemes, some detected in error, into a stream of words in the target language. With out earlier neural networks the feature detectors that were applied to raw sound signals to provide low level clues for phonemes were programs that engineers had built by hand. With Deep Learning, techniques were developed where those earliest features were also learned by listening to massive amounts of speech from different speakers all talking in the target language. This is why today we are starting to think it natural to be able to talk to our machines. Just like Scotty did in Star Trek 4: The Voyage Home.
A new capability was unveiled to the world in a New York Times story on November 17, 2014 where the photo below appeared along with a caption that a Google program had automatically generated: “A group of young people playing a game of Frisbee”.
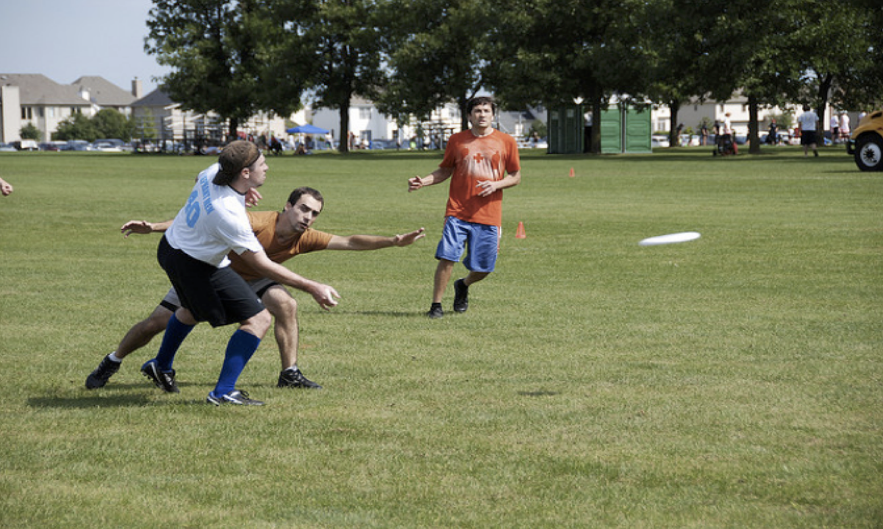
I think this is when people really started to take notice of Deep Learning. It seemed miraculous, even to AI researchers, and perhaps especially to researchers in symbolic AI, that a program could do this well. But I also think that people confused performance with competence (referring again to my seven deadly sins post). If a person had this level of performance, and could say this about that photo, then one would naturally expect that the person had enough competence in understanding the world, that they could probably answer each of the following questions:
- what is the shape of a Frisbee?
- roughly how far can a person throw a Frisbee?
- can a person eat a Frisbee?
- roughly how many people play Frisbee at once?
- can a 3 month old person play Frisbee?
- is today’s weather suitable for playing Frisbee?
But the Deep Learning neural network that produced the caption above can not answer these questions. It certainly has no idea what a question is, and can only output words, not take them in, but it doesn’t even have any of the knowledge that would be needed to answer these questions buried anywhere inside what it has learned. It has learned a mapping from colored pixels, with a tiny bit of spatial locality, to strings of words. And that is all. Those words only rise up a little beyond the anonymous symbols of traditional AI research, to have a sort of grounding, a grounding in the appearance of nearby pixels. But beyond that those words or symbols have no meanings that can be related to other things in the world.
Note that the medium in which learning happens here is selecting many hundreds of thousands, perhaps millions, of numbers or weights. The way that the network is connected to input data is designed by a human, the layout of the network is designed by a human, the labels, or symbols, for the outputs are selected by a human, and the set of training data has previously been labelled by a human (or thousands of humans) with these same symbols.
3. Traditional Robotics
In the very first decades of Artificial Intelligence, the AI of symbols, researchers sought to ground AI by building robots. Some were mobile robots that could move about and perhaps push things with their bodies, and some were robot arms fixed in place. It was just too hard then to have both, a mobile robot with an articulated arm.
The very earliest attempts at computer vision were then connected to these robots, where the goal was to, first, deduce the geometry of what was in the world, and then to have some simple mapping to symbols, sitting on top of that geometry.
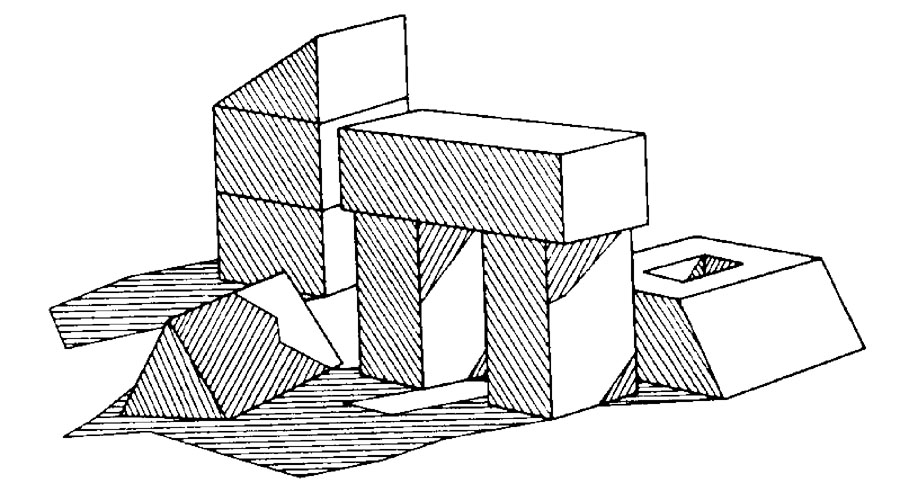
In my post on the origins of AI I showed some examples of how perception was built up by looking for edges in images, and then working through rules on how edges might combine in real life to produce geometric models of what was in the world. I used this example of a complex scene with shadows:
In connecting cameras to computers and looking at the world, the lighting and the things allowed in the field of view often had to be constrained for the computer vision, the symbol grounding, to be successful. Below is a really fuzzy picture of the “copy-demo” at the MIT Artificial Intelligence Laboratory in 1970. Here the vision system looked at a stack of blocks and the robot tried to build a stack that looked the same.

At the same time a team at SRI International in Menlo Park, California, were building the robot Shakey, which operated in a room with large blocks, cubes and wedges, with each side painted in a different matte color, and with careful control of lighting.


By 1979 Hans Moravec at the Stanford Artificial Intelligence Lab had an outdoor capable robot, “The Cart”, in the center of the image here (a photograph that I took), which navigated around polyhedral objects, and other clutter. Since it took about 15 minutes to move one meter it did get a little confused by the high contrast moving shadows.

And here is the Freddy II robot at the Department of Artificial Intelligence at Edinburgh University in the mid 1970’s, stacking flat square and round blocks and inserting pegs into them.

These early experiments combined image to symbol mapping, along with extracting three dimensional geometry so that the robot could operate, using symbolic AI planning programs from end to end.
I think it is fair to say that those end to end goals have gotten a little lost over the years. As the reality of complexities due to uncertainties when real objects are used have been realized, the tasks that AI robotics researchers focus on have been largely driven by a self defined research agenda, with proof of concept demonstrations as the goal.
And I want to be clear here. These AI based robotics systems are not used at all in industry. All the robots you see in factories (except those from my company, Rethink Robotics) are carefully programmed, in detail, to do exactly what they are doing, again, and again, and again. Although the lower levels of modeling robot dynamics and planning trajectories for a robot arm are shared with the AI robotics community, above that level it is very complete and precise scripting. The last forty years of AI research applied to factory robots has had almost no impact in practice.
On the other hand there has been one place from traditional robotics with AI that has had enormous impact. Starting with robots such as The Cart, above, people tried to build maps of the environment so that the system could deliberatively plan a route from one place to another which was both short in time to traverse and which would avoid obstacles or even rough terrain. So they started to build programs that took observations as the robot moved and tried to build up a map. They soon realized that because of uncertainties in how far the robot actually moved, and even more importantly what angle it turned when commanded, it was impossible to put the observations into a simple coordinate system with any certainty, and as the robot moved further and further the inaccuracies relative to the start of the journey just got worse and worse.
In late 1984 both Raja Chatila from Toulouse, and I, newly a professor at MIT, realized that if the robot could recognize when it saw a landmark a second time after wandering around for a while it could work backwards through the chain of observations made in between, and tighten up all their uncertainties. We did not need to see exactly the same scene as before, all we needed was to locate one of the things that we had earlier labeled with a symbol, and being sure that the new thing we saw labelled by the same symbol as in fact the same object in the world. This is now called “loop closing” and we independently published papers with this idea in March 1985 at a robotics conference held in St Louis (IEEE ICRA). But neither of us had very good statistical models, and mine was definitely worse than Raja’s.
By 1991 Hugh Durrant-Whyte and John Leonard, then both at Oxford, had come up with a much better formalization, which they originally called “Simultaneous Map Building and Localisation” (Oxford English spelling), which later turned into “Simultaneous Localisation and Mapping” or SLAM. Over the next fifteen years, hundreds, if not thousands, of researchers refined the early work, enabled by newly low cost and plentiful mobile robots (my company iRobot was supplying those robots as a major business during the 1990’s). With a formalized well defined problem, low cost robots, adequate computation, and researchers working all over the world, competing on performance, there was rapid progress. And before too long the researchers managed to get rid of symbolic descriptions of the world and do it all in geometry with statistical models of uncertainty.
The SLAM algorithms became part of the basis for self-driving cars, and subsystems derived from SLAM are used in all of these systems. Likewise the navigation and data collection from quadcopter drones is powered by SLAM (along with inputs from GPS).
4. Behavior-Based Robotics
By 1985 I had spent a decade working in computer vision, trying to extract symbolic descriptions of the world from images, and in traditional robotics, building planning systems for robots to operate in simulated or actual worlds.
I had become very frustrated.
Over the previous couple of years as I had tried to move from purely simulated demonstrations to getting actual robots to work in the real world, I had become more and more buried in mathematics that was all trying to estimate the uncertainty in what my programs knew about the real world. The programs were trying to measure the drift between the real world, and the perceptions that my robots were making of the world. We knew by this time that perception was difficult, and that neat mapping from perception to certainty was impossible. I was trying to accommodate that uncertainty and push it through my planning programs, using a mixture of traditional robotics and symbolic Artificial Intelligence. The hope was that by knowing how wide the uncertainty was the planners could accommodate all the possibilities in the actual physical world.
I will come back to the implicit underlying philosophical position that I was taking in the last major blog post in this series, to come out later this year.
But then I started to reflect on how well insects were able to navigate in the real world, and how they were doing so with very few neurons (certainly less that the number of artificial neurons in modern Deep Learning networks). In thinking about how this could be I realized that the evolutionary path that had lead to simple creatures probably had not started out by building a symbolic or three dimensional modeling system for the world. Rather it must have begun by very simple connections between perceptions and actions.
In the behavior-based approach that this thinking has lead to, there are many parallel behaviors running all at once, trying to make sense of little slices of perception, and using them to drive simple actions in the world. Often behaviors propose conflicting commands for the robot’s actuators and there has to be a some sort of conflict resolution. But not wanting to get stuck going back to the need for a full model of the world, the conflict resolution mechanism is necessarily heuristic in nature. Just as one might guess, the sort of thing that evolution would produce.
Behavior-based systems work because the demands of physics on a body embedded in the world force the ultimate conflict resolution between behaviors, and the interactions. Furthermore by being embedded in a physical world, as a system moves about it detects new physical constraints, or constraints from other agents in the world. For synthetic characters in video games under the control of behavior trees, the demands of physics are replaced by the demands of the simulated physics needed by the rendering engine, and other agents in the world are either the human player of yet more behavior-based synthetic characters.
Just in the last few weeks there has been a great example of this that has gotten a lot of press. Here is the original story about MIT Professor Sangbae Kim’s Cheetah 3 robot. The press was very taken with the robot blindly climbing stairs, but if you read the story you will see that the point of the research is not to produce a blind robot per se. Computer vision, even 3-D vision, is not completely accurate. So any robot that tries to climb rough terrain using vision, rather than feel, needs to be very slow, careful placing its feet one at a time, as it does not know exactly where the solid support in the world is. In this new work, Kim and his team have built a collection of low level behaviors which sense when things have gone wrong and quickly adapt individual legs. To prove the point, they made the robot completely blind–the performance of their robot will only increase as vision gives some high level direction to where the robot should aim its feet, but even so, having these reactive behaviors at the lowest levels make it much faster and more sure footed.
The behavior-based approach, which leaves the model out in the world rather than inside the agent, has allowed robots to proliferate in number. Unfortunately, I often get attacked by people outside the field, saying in effect, we were promised super intelligent robots and all you have given us is robot vacuum cleaners. Sorry, it is a work in progress. At least I gave you something practical…
Comparing The Four Approaches to AI
In my 1990 paper Elephants Don’t Play Chess, in the first paragraph of the second page I mentioned that the “holy grail” for both classical symbolic AI research, and my own research was “general purpose human level intelligence”–the youngsters today saying that the goal of AGI, or Artificial General Intelligence is a new thing are just plain wrong. All four of the approaches I outlined above have been motivated by eventually getting to human level intelligence, and perhaps beyond.
None of them are yet close by themselves, nor have any combinations of them turned into something that seems close. But each of the four approaches has somewhat unique strengths. And all of them have easily identifiable weaknesses.
The use of symbols in AI research allows one to use them as the currency of composition between different aspects of intelligence, passing the symbols from one reasoning component to another. For neural networks fairly weak symbols appear only as outputs and there is no way to feed them back in, or really to other networks. Traditional robotics trades on geometric relationships and coordinates, which means they are easy to compose, but they are very poor in semantic content. And behavior-based systems are sub-symbolic, although there are ways to have some sorts of proto symbols emerge.
Neural networks have been the most successful approach to getting meaningful symbols out of perceptual inputs. The other approaches either don’t try to do so (traditional robotics) or have not been particularly successful at it.
Hard local coordinate systems, with solid statistical relationships between them have become the evolved modern approach to traditional robotics. Both symbolic AI and behavior based systems are weak in having different parts of the systems relate to common, or even well understood relative, coordinate systems. And neural networks simply suck (yes, suck) at spatial understanding.
Of the four approaches to AI discussed here, only the behavior-based approach makes a commitment to an ongoing existence of the system, the others, especially neural networks are much more transactional in nature. And the behavior-based approach reacts to changes in the world on millisecond timescales, as it is embedded, and “living” in the real world. Or in the case of characters in video games, it is well embedded in the matrix. This ability to be part of the world, and to have agency within it is at some level an artificial sentience. A messy philosophical term to be sure. But I think all people who ever utter the phrase Artificial General Intelligence, or utter, or mutter, Super Intelligence, are expecting some sort of sentience. No matter how far from reality the sentience of behavior-based systems may be, it is the best we have got. By a long shot.
I have attempted to score the four approaches on where they are better and where worse. The scale is one to three with three being a real strength of the approach. Notice that besides the four different strengths I have added a column for how well the approaches deal with ambiguity.
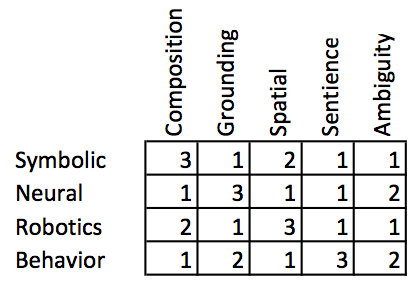
These are very particular capabilities that one or the other of the four approaches does better at. But for general intelligence I think we need to talk about cognition. You can find many definitions of cognition but the all have to do with thinking. And the definitions talk about thinking variously in the context of attention, memory, language understanding, perception, problem solving and others. So my scores are going to be a little subjective, I admit.
If we think about a Super Intelligent AI entity, one might want it to act in the world with some sort of purpose. For symbolic AI and traditional robotics there have been a lot of work on planners, programs that look at the state of the world and try to work out a series of actions that will get the world (and the embedded AI system or robot) into a more desirable state. These planners, largely symbolic, and perhaps with a spatial component for robots, started out relying on full knowledge of the state of the world. In the last couple of decades that work has concentrated on finessing the impossibility of knowing the state of the world in detail. But such planners are quite deliberative in working out what is going to happen ahead of time. By contrast the behavior based approaches started out as purely reactive to how the world was changing. This has made them much more robust in the real world which is why the vast majority of deployed robots in the world are behavior-based. With the twenty year old innovation of behavior trees these systems can appear much more deliberative, though they lack the wholesale capability of dynamically re-planning that symbolic systems have. This table summarizes:
Note that neural nets are neither. There has been a relatively small amount of non-mainstream work of getting neural nets to control very simple robots, mostly in simulation only. The vast majority of work on neural networks has been to get them to classify data in some way or another. They have never been a complete system, and indeed all the recent successes of neural networks have had them embedded as part of symbolic AI systems or behavior-based systems.
To end Part I of our Steps Towards Super Intelligence, let’s go back to our comparison of the four approaches to Artificial Intelligence. Let’s see how well we are really doing (in my opinion) by comparing them to a human child.
Recall the scale here is one to three. I have added a column on the right on how well they do at cognition, and a row on the bottom on how well a human child does in comparison to each of the four AI approaches. One to three.
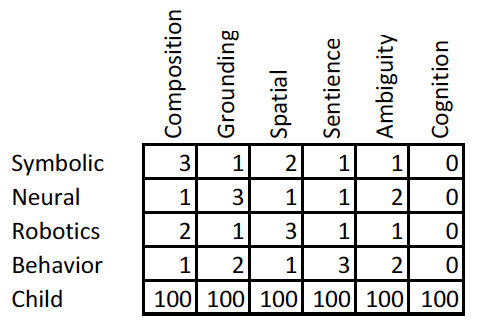
Note that under this evaluation a human child scores six hundred points whereas the four AI approaches score a total of eight or nine points each. As usual, I think I may have grossly overestimated the current capabilities of AI systems.
Next up: Part II, beyond the Turing Test.
1 This pronoun is often capitalized in this quote, but in my version of the King James Bible, which was presented to my grandmother in 1908, it is just plain “his” without capitalization. Genesis 1:27.
2 In the dedication of this 1973 PhD thesis at the MIT Artificial Intelligence Lab, to the Maharal of Prague–the creator of the best known Golem, Gerry Sussman points out that the Rabbi had noticed that this line was recursive. That observation has stayed with me since I first read it in 1979, and it inspired my first two lines of this blog post.
3 I am using the male form here only for stylistic purposes to resonate with the first sentence.
4 It appeared in the IEEE Journal of Robotics and Automation, Vol. 2, No. 1, March 1986, pp 14–23. Both reviewers for the paper recommended against publishing it, but the editor, Professor George Bekey of USC, used his discretion to override them and to go ahead and put it into print.
5 I chose this form, g0047, for anonymous symbols as that is exactly the form in which they are generated in the programming language Lisp, which is what most early work in AI was written in, and is still out there being used to do useful work.