

[This is the fourth part of a four part essay–here is Part I.]
We have been talking about building an Artificial General Intelligence agent, or even a Super Intelligence agent. How are we going to get there? How are we going get to ECW and SLP? What do researchers need to work on now?
In a little bit I’m going to introduce four pseudo goals, based on the capabilities and competences of children. That will be my fourth big list of things in these four parts of this essay. Just to summarize so the numbers and lists don’t get too confusing here is what I have described and proposed over these four sub essays:
| Part I | 4 Previous approaches to AI | |
| Part II | 2 New Turing Test replacements | |
| Part III | 7 (of many) things that are currently hard for AI | |
| Part IV | 4 Ways to make immediate progress |
But what should AI researchers actually work on now?
I think we need to work on architectures of intelligent beings, whether they live in the real world or in cyber space. And I think that we need to work on structured modules that will give the base compositional capabilities, ground everything in perception and action in the world, have useful spatial representations and manipulations, provide enough ability to react to the world on short time scales, and to adequately handle ambiguity across all these domains.
First let’s talk about architectures for intelligent beings.
Currently all AI systems operate within some sort of structure, but it is not the structure of something with ongoing existence. They operate as transactional programs that people run when they want something.
Consider AlphaGo, the program that beat 18 time world Go champion, Lee Sedol, in March of 2016. The program had no idea that it was playing a game, that people exist, or that there is two dimensional territory in the real world–it didn’t know that a real world exists. So AlphaGo was very different from Lee Sedol who is a living, breathing human who takes care of his existence in the world.
I remember seeing someone comment at the time that Lee Sedol was supported by a cup of coffee. And Alpha Go was supported by 200 human engineers. They got it processors in the cloud on which to run, managed software versions, fed AlphaGo the moves (Lee Sedol merely looked at the board with his own two eyes), played AlphaGo’s desired moves on the board, rebooted everything when necessary, and generally enabled AlphaGo to play at all. That is not a Super Intelligence, it is a super basket case.
So the very first thing we need is programs, whether they are embodied or not, that can take care of their own needs, understand the world in which they live (be it the cloud or the physical world) and ensure their ongoing existence. A Roomba does a little of this, finding its recharger when it is low on power, indicating to humans that it needs its dust bin emptied, and asking for help when it gets stuck. That is hardly the level of self sufficiency we need for ECW, but it is an indication of the sort of thing I mean.
Now about the structured modules that were the subject of my second point.
The seven examples I gave, in Part III, of things which are currently hard for Artificial Intelligence, are all good starting points. But they were just seven that I chose for illustrative purposes. There are a number of people who have been thinking about the issue, and they have come up with their own considered lists.
Some might argue, based on the great success of letting Deep Learning learn not only spoken words themselves but the feature detectors for early processing of phonemes that we are better off letting learning figure everything out. My point about color constancy is that it is not something that naturally arises from simply looking at online images. It comes about in the real world from natural evolution building mechanisms to compensate for the fact that objects don’t actually change their inherent color when the light impinging on them changes. That capability is an innate characteristic of evolved organisms whenever it matters to them. We are most likely to get there quicker if we build some of the important modules ahead of time.
And for the hard core learning festishists here is a question to ask them. Would they prefer that their payroll department, their mortgage provider, or the Internal Revenue Service (the US income tax authority) use an Excel spreadsheet to calculate financial matters for them, or would they trust these parts of their lives to a trained Deep Learning network that had seen millions of examples of spreadsheets and encoded all that learning in weights in a network? You know what they are going to answer. When it comes to such a crunch even they will admit that learning from examples is not necessarily the best approach.
Gary Marcus, who I quoted along with Ernest Davis about common sense in Part III, has talked about his list of modules1 that are most important to build in. They are:
- Representations of objects
- Structured, algebraic representations
- Operations over variables
- A type-token distinction
- A capacity to represent sets, locations, paths, trajectories, obstacles and enduring individuals
- A way of representing the affordances of objects
- Spatiotemporal contiguity
- Causality
- Translational invariance
- Capacity for cost-benefit analysis
Others will have different explicit lists, but as long as people are working on innate modules that can be combined within a structure of some entity with an ongoing existence and its own ongoing projects, that can be combined within a system that perceives and acts on its world, and that can be combined within a system that is doing something real rather than a toy online demonstration, then progress will be being made.
And note, we have totally managed to avoid the question of consciousness. Whether either ECW or SLP need to conscious in any way at all, is, I think, an open question. And it will remain so as long as we have no understanding at all of consciousness. And we have none!
HOW WILL WE KNOW IF WE ARE GETTING THERE?
Alan Turing introduced The Imitation Game, in his 1950 paper Computing Machinery and Intelligence. His intent was, as he said in the very first sentence of the paper, to consider the question “Can Machines Think?”. He used the game as a rhetorical device to discuss objections to whether or not a machine could be capable of “thinking”. And while he did make a prediction of when a machine would be able to play the game (a 70% change of fooling a human that the machine was a human in the year 2000), I don’t think that he meant the game as a benchmark for machine intelligence.
But the press, over the years, rather than real Artificial Intelligence researchers, picked up on this game and it became known as the Turing Test. For some, whether or not a machine could beat a human at this parlor game, became the acid test of progress in Artificial Intelligence. It was never a particularly good test, and so the big “tournaments” organized around it were largely ignored by serious researchers, and eventually pretty dumb chat bots that were not at all intelligent started to get crowned as the winners.
Meanwhile real researchers were competing in DARPA competitions such as the Grand Challenge, Urban Grand Challenge (which lead directly to all the current work on self driving cars), and the Robot Challenge.
We could imagine tests or competitions being set up for how well an embodied and a disembodied Artificial Intelligence system perform at the ECW and SLP tasks. But I fear that like the Turing Test itself these new tests would get bastardized and gamed. I am content to see the market choose the best versions of ECW and SLP–unlike a pure chatterer that can game the Turing Test, I think such systems can have real economic value. So no tests or competitions for ECWs and SLPs.
I have never been a great fan of competitions for research domains as I have always felt that it leads to group think, and a lot of effort going into gaming the rules. And, I think that specific stated goals can lead to competitions being formed, even when none may have been intended, as in the case of the Turing Test.
Instead I am going to give four specific goals here. Each of them is couched in terms of the competence of capabilities of human children of certain ages.
- The object recognition capabilities of a two year old.
- The language understanding capabilities of a four year old.
- The manual dexterity of a six year old.
- The social understanding of an eight year old.
Like most people’s understanding of what is pornography or art there is no formal definition that I want to use to back up these goals. I mean them in the way that generally informed people would gauge the performance of an AI system after extended interaction with it, and assumes that they would also have had extended interactions with children of the appropriate age.
These goals are not meant to be defined by “performance tests” that children or an AI system might take. They are meant as unambiguous levels of competence. The confusion between performance and competence was my third deadly sin in my recent post about the mistakes people make in understanding how far along we are with Artificial Intelligence.
If we are going to make real progress towards super, or just every day general, Artificial Intelligence then I think it is imperative that we concentrate on general competence in areas rather than flashy hype bait worthy performances.
Down with performance as a measure, I say, and up with the much fuzzier notion of competence as a measure of whether we are making progress.
So what sort of competence are we talking about for each of these for cases?
2 year old Object Recognition competence. A two year old already has color constancy, and can describe things by at least a few color words. But much more than this they can handle object classes, mapping what they see visually to function.
A two year old child can know that something is deliberately meant to function as a chair even if it is unlike any chair they have seen before. It can have a different number of legs, it can be made of different material, its legs can be shaped very oddly, it can even be a toy chair meant for dolls. A two year old child is not fazed by this at all. Despite having no visual features in common with any other chair the child has ever seen before the child can declare a new chair to be a chair. This is completely different from how a neural network is able to classify things visually.
But more than that, even, a child can see something that is not designed to function as a chair, and can assess whether the object, or location can be used as a chair. The can see a rock and decide that it can be sat upon, or look for a better place where there is something that will functionally act as a seat back.
So two year old children have sophisticated understandings of classes of objects. Once, while I was giving a public talk, a mother felt compelled to leave with her small child who was making a bit of a noisy fuss. I called her back and asked her how old the child was. “Two” came the reply. Perfect for the part of the talk I was just getting to. Live, with the audience watching I made peace with the little girl and asked if she could come up on stage with me. Then I pulled out my key ring, telling the audience that this child would be able to recognize the class of a particular object that she had never seen before. Then I held up one key and asked the two year old girl what it was. She looked at me with puzzlement. Then said, with a little bit of scorn in her voice, “a key”, as though I was an idiot for not knowing what it was. The audience loved it, and the young girl was cheered by their enthusiastic reaction to her!
But wait, there is more! A two year old can do one-shot visual learning from multiple different sources. Suppose a two year old has never been exposed to a giraffe in any way at all. Then seeing just one of a hand drawn picture of a giraffe, a photo of a giraffe, a stuffed toy giraffe, a movie of a giraffe, or seeing one in person for just a few seconds, will forever lock the concept of a giraffe into that two year old’s mind. That child will forever be able to recognize a giraffe as a giraffe, whatever form it is represented in. Most people have never seen a live giraffe, and none have ever seen a live dinosaur, but the are easy for anyone to recognize.
Try that, Deep Learning. One example, in one form!
4 year old Language Understanding competence. Most four year old children can not read or write, but they can certainly talk and listen. They well understand the give and take of vocal turn-taking, know when they are interrupting, and know when someone is interrupting them. They understand and use prosody to great effect, along with animation of their faces, heads and whole bodies. Likewise they read these same cues from other speakers, and make good use of both projecting and detecting gaze direction in conversations amongst multiple people, perhaps as side conversations occur.
Four year old children understand when they are in conversation with someone, and (usually) when that conversation has ended, or the participants have changed. If there are three of four people in a conversation they do not need to name who they are delivering remarks to, nor to hear their name at the beginning of an utterance in order to understand when a particular remark is directed at them–they use all the non-spoken parts of communication to make the right inferences.
All of this is very different from today’s speech with agents such as the Amazon Echo, or Google Home. It is also different in that a four year old child can carry the context generated by many minutes of conversation. They can understand incomplete sentences, and can generate short meaningful interjections of just a word or two that make sense in context and push forward everyone’s mutual understanding.
A four year old child, like the remarkable progress in computer speech understanding over the last five years due to Deep Learning, can pick out speech in noisy environments, tuning out background noise and concentrating on speech directed at them, or just what they want to hear from another ongoing conversation not directed at them. They can handle strong accents that they have never heard before and still extract accurate meaning in discussions with another person.
They can deduce gender and age from the speech patterns of another, and they are finely attuned to someone they know speaking differently than usual. They can understand shouted, whispered, and sung speech. They themselves can sing, whisper and shout, and often do so appropriately.
And they are skilled in the complexity of sentences that they can handle. They understand many subtleties of tense, they can talk in and understand hypotheticals. Then can engage in and understand nonsense talk, and weave a pattern of understanding through it. They know when the are lying, and can work to hide that fact in their speech patterns.
They are so much more language capable than any of our AI systems, symbolic or neural.
6 year old Manual Dexterity competence. A six year old child, unless some super prodigy, is not able to play Chopin on the piano. But they are able to do remarkable feats of manipulation, with their still tiny hands, that no robot can do. When they see an object for the first time they fairly reliably estimate whether they can pick it up one handed, two handed, or two arms and whole body (using their stomach or chests as an additional anchor region), or not at all. For a one handed grasp they preshape their hand as they reach towards it having decided ahead of time what sort of grasp they are going to use. I’m pretty sure that a six old can do all these human grasps:
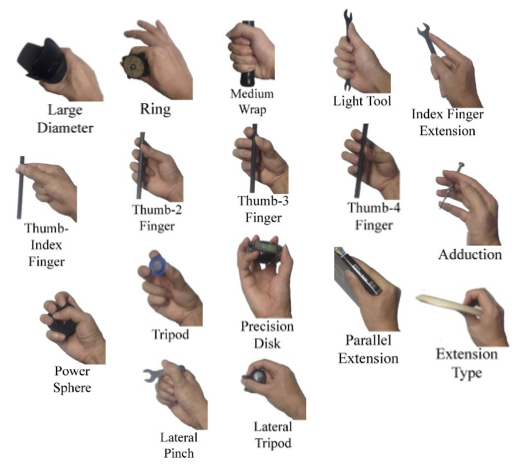
[I do not know the provenance of this image–I found it at a drawing web site here.] A six year old can turn on faucets, tie shoe laces, write legibly, open windows, raise and lower blinds if they are not too heavy, and they can use chopsticks in order to eat, even with non-rigid food. They are quite dexterous. With a little instruction they can cut vegetables, wipe down table tops, open and close food containers, open and close closets, and lift stacks of flat things into and out of those closets.
Six year old children can manipulate their non-rigid clothes, fold them, though not as well as skilled adult (I am not a skilled adult in this regard…), manipulate them enough to put them on and off themselves, and their dolls.
Furthermore, they can safely pick up a cat and even a moderately sized dog, and often are quite adept and trustworthy picking up their very young siblings. They can caress their grandparents.
They can wipe their bums without making a mess (most of the time).
ECW will most likely need to be able to do all these things, with scaled up masses (e.g., lifting or dressing a full sized adult which is beyond the strength capabilities of a six year old child).
We do not have any robots today that can do any of these things in the general case where a robot can be placed in a new environment with new instances of objects that have not been seen before, and do any of these tasks.
Going after these levels of manipulation skill will result in robots backed by new forms of AI that can do the manual tasks that we expect of humans, and that will be necessary for giving care to other humans.
8 year old Social Understanding competence. By age eight children are able to articulate their own beliefs, desires, and intentions, at least about concrete things in the world. They are also able to understand that other people may have different beliefs, desires, and intentions, and when asked the right questions can articulate that too.
Furthermore, they can reason about what they believe versus what another person might believe and articulate that divergence. A particular test for this is known as the “false-belief task”. There are many variations on this, but essentially what happens is that an experimenter lets a child see a person make an observation of a person seeing that Box A contains, say, a toy elephant, and that Box B is empty. That person leaves the room, and the experimenter then, in full sight of the child moves the toy elephant to Box B. They then ask the child which box contains the toy elephant, and of course the child says Box B. But the crucial question is to ask the child where the person who left the room will look for the toy elephant when they are asked to find it after they have come back into the room. Once the child is old enough (and there are many experiments and variations here) they are able to tell the experimenter that the person will look in Box A, knowing that is based on a belief the person has which is now factually false.
There is a vast literature on this and many other aspects of understanding other people, and also a vast literature on testing such knowledge for very young children but also for chimpanzees, dogs, birds, and other animals on what they might understand–without the availability of language these experiments can be very hard to design.
And there are many many aspects of social understanding, including inferring a person’s desire or intent from their actions, and understanding why they may have those desires and intents. Some psychological disorders are manifestations of not being able to make such inferences. But in our normal social environment we assume a functional capability in many of these areas about others with whom we are interacting. We don’t feel the need to explain certain things to others as surely they will know from what they are observing. And we also observe the flow of knowledge ourselves and are able to make helpful suggestions as we see people acting in the world. We do this all the time, pointing to things, saying “over there”, or otherwise being helpful, even to complete strangers.
Social understanding is the juice that makes us humans into a coherent whole. And, we have versions of social understanding for our pets, but not for our plants. Eight year old children have enough of it for much of every day life.
Improvement in Competence will lead the way
These competencies of two, four, six, and eight year old children will all come into play for ECW and SLP. Without these competencies, our intelligent systems will never seem natural or as intelligent as us. With these competencies, whether they are implemented in ways copied from humans or not (birds vs airplanes) our intelligent systems will have a shot at appearing as intelligent as us. They are crucial for an Artificial Generally Intelligent system, or for anything that we will be willing to ascribe Super Intelligence to.
So, let’s make progress, real progress, not simple hype bait, on all four of these systems level goals. And then, for really the first time in sixty years we will actually be part ways towards machines with human level intelligence and competence.
In reality it will just be a small part of the way, and even less of the way to towards Super Intelligence.
It turns out that constructing deities is really really hard. Even when they are in our own image.
1 “Innateness, AlphaZero, and Artificial Intelligence“, Gary Marcus, submitted to arXiv, January 2018.
Thank you Dr. Brooks for writing this article (and all your other ones)! As a current PhD student studying AI/Robotics, you have fundamentally changed the way I am thinking about approaching the field, and am extremely excited to read more of your thoughts to better form my own (and what I’d like to do with it!). Thank you for taking the time to share these writings with the world, I am truly changed because of them.