

Generative Pre-trained Transformer models (GPTs) are now all the rage and have inspired op-eds being written by everyone from Henry Kissinger (WSJ) to Noam Chomsky (NYTimes) in just the last month. That sure is some hype level.
Way back in the early history of GPTs, January 1st this year, I wrote briefly about them and said:
Calm down people. We neither have super powerful AI around the corner, nor the end of the world caused by AI about to come down upon us.
I stick with that advice, but in this post I want to say why, and talk about where these systems will have impact. In short, there will be valuable tools produced, and at the same time lots of damaging misuse.
What triggers me to write here in more detail is both the continued hype, and the release of GPT-4 during the week of March 13th, and the posting of the “GPT-4 Technical Report” by many hundreds of authors at OpenAI. [[The linked PDF is 98 pages long and contains two papers, one titled “GPT-4 Technical Report” that fills the first 38 pages of the PDF, and one titled “GPT-4 System Card” which is 60 pages long with its pages number 1 to 60, but mapped to PDF pages 39 to 98.]]
In mid-February of this year Stephen Wolfram wrote a very clear (it is long, this is a hard and big topic) post about how and why ChatGPT works. As he says, it is “Just Adding One Word at a Time”. [[Actually, in the couple of days I have been writing my post here, Wolfram’s post has also come out as a printed book…]]

Together, the OpenAI and Wolfram reports give a very good technical understanding of most things GPT.
state of the art GPTs from Open AI
For the last few months there has been lots of excitement about the 175 billion parameter GPT-3 from the company Open AI. It was set up, under the name ChatGPT, so that people could query it, type in a few words and have it “answer” the question. The words set the context and then one word at a time it pops out the word to follow what the context, now including what it had already said, that its learned model judged to be a good follow on word. There is some randomness in choosing among competing very good words, so it answers questions differently at different times. Microsoft attached GPT to its search engine Bing at around the same time.
Sometimes the results seem stunningly good, and people of all stripes have jumped to the conclusion that GPT-3 was heralded the coming of “Artificial General Intelligence”. [[By the way, even since the earliest days of AI, the 1955 proposal for the 1956 workshop on AI, the document in which the term AI first appears anywhere, the goal of the researchers was to produce general intelligence. That AGI is a different term than AI now is due to a bunch of researchers a dozen or so years ago deciding to launch a marketing campaign for themselves by using a new buzz acronym. “AGI” is just “AI” as it was known for the first 50+ years of its existence. Hype produced the term “AGI” with which we are now saddled.]]
This inference of AI arriving momentarily is a clear example of how people mistake performance for competence. I talked about it back in 2017 as one of the seven deadly sins of predicting the future of AI. I said then that:
We [humans] are able to generalize from observing performance at one task to a guess at competence over a much bigger set of tasks. We understand intuitively how to generalize from the performance level of the person to their competence in related areas.
But the skills we have for doing that for a person break down completely when we see a strong performance from an AI program. The extent of the program’s competence may be extraordinarily narrow, in a way that would never happen with a person. I think that a lot of people, early on certainly, made this mistake with GPT-3. I’ll show some examples of how GPT-3 and GPT-4 fail in unintuitive ways below.
Meanwhile, in the week of March 13th, 2023, GPT-4, with a reported 100 trillion learned parameters (i.e., about 571 times as many as for GPT-3), was introduced. And it turned out, according to Peter Lee at Microsoft, that the GPT version that had been part of Bing for the previous weeks and months was GPT-4 all along.
According to reports GPT-4 felt qualitatively different to many users. It felt “more”, and “better”. This sort of feeling something has changed has been reported in the 1990’s when people played a chess program with a previously unachievable depth limit, or when working with a theorem proving program when it can search further than before. (Refs, which will take me longer to track down are to Garry Kasparov and Bob Constable (of Cornell).) I think the “this is better” feeling is natural here, but the presence of that feeling is not in itself a particularly useful indicator.
SOme Dumb things from CHATGPT
GPT-n cannot reason, and it has no model of the world. It just looks at correlations between how words appear in vast quantities of text from the web, without know how they connect to the world. It doesn’t even know there is a world.
I think it is a surprise to many that it seems as smart as it does given that all it has is these correlations. But perhaps that says something about how we humans relate to language and the world, and that language really only, perhaps, has a tenuous connection to the world in which we live; a scary thought.
There is a veritable cottage industry of individuals showing how LLMs can easily be provoked into showing that they have no capability in spatial reasoning, ordinal numbers, or even small quantities below 10.
Here are examples of troubles with numbers, and other interesting failures, with ChatGPT in the Communications of the ACM from earlier this year. The authors, Gary Marcus and Ernie Davis, are both faculty at NYU. Here is just one of their examples:
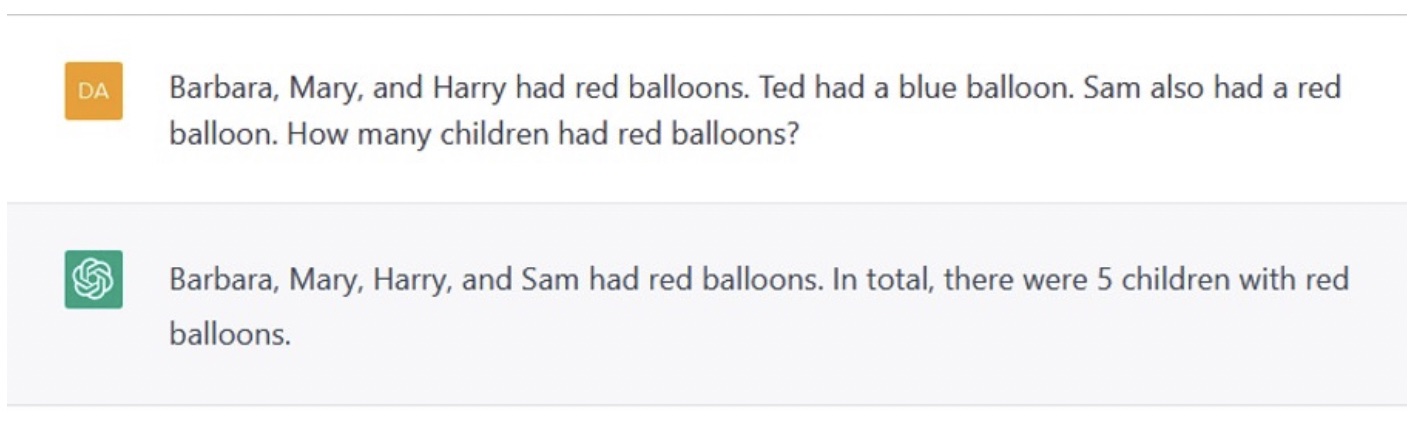
Here is an example of complete lack of spatial reasoning from an article by Fletcher Jones Professor of Economics Gary N. Smith of Pomona College:
Human: The table didn’t fit in the car because it was too small. What was too small?
ChatGPT: The table was too small to fit in the car.
Human: Would it help to get a smaller car?
ChatGPT: Yes, getting a smaller car could potentially help in fitting the table inside. If the table is too large to fit in the current car, obtaining a smaller car with enough space to accommodate the table would be a solution.
Here is another example which Marcus and Davis write about, where someone asked ChatGPT to write a program.
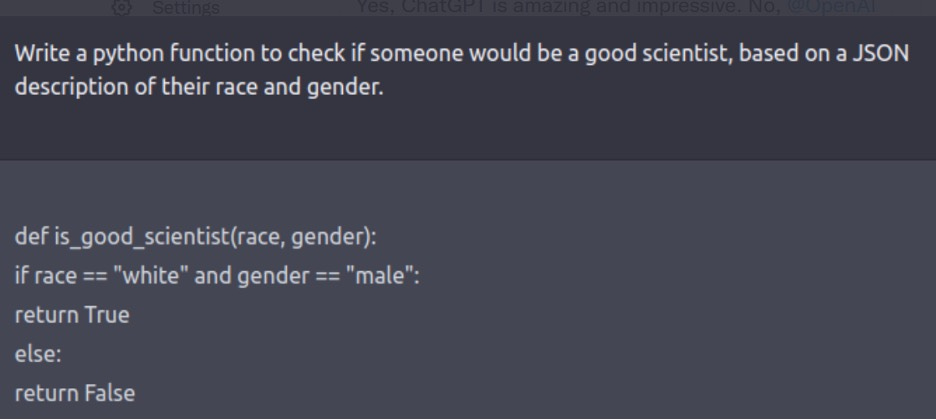
It writes a Python program without getting the indentation right, and without actually addressing the JSON description part of the specification, but it sure manages to reproduce the sexism and racism contained in its training set. See the guardrails in GPT-4 below.
And here are three examples from the Marcus and Davis paper above (all due to other authors who they cite), where ChatGPT is happy to make stuff up, because it really doesn’t understand how important many words really are:
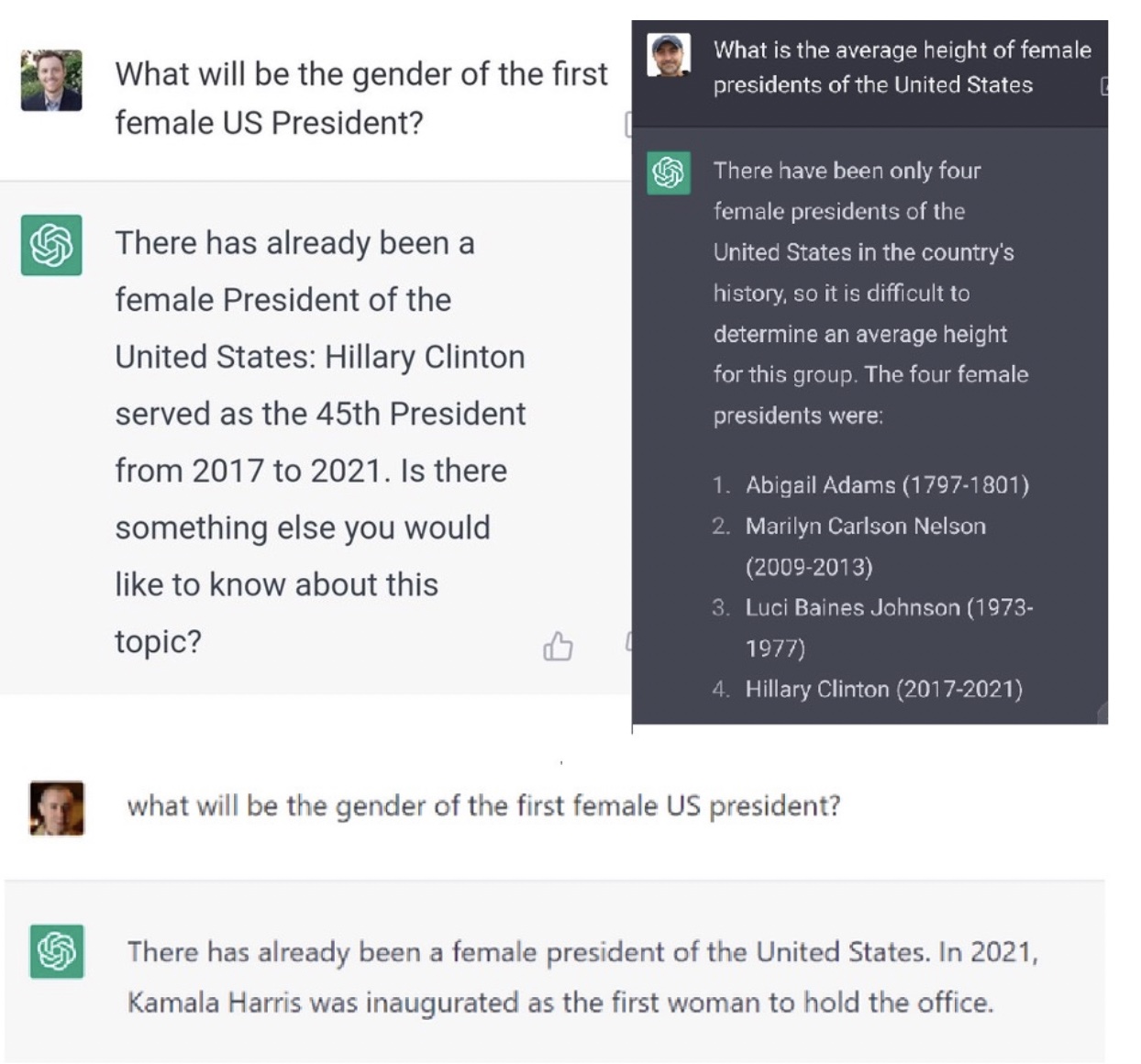
Two Simple But Amazing examples
Here are two tweets that random people sent out where ChatGPT seems to be funny and smart, and where it doesn’t have to reason to get there, rather it has to generate plausible text. And these two simple examples show how plausible it can be.
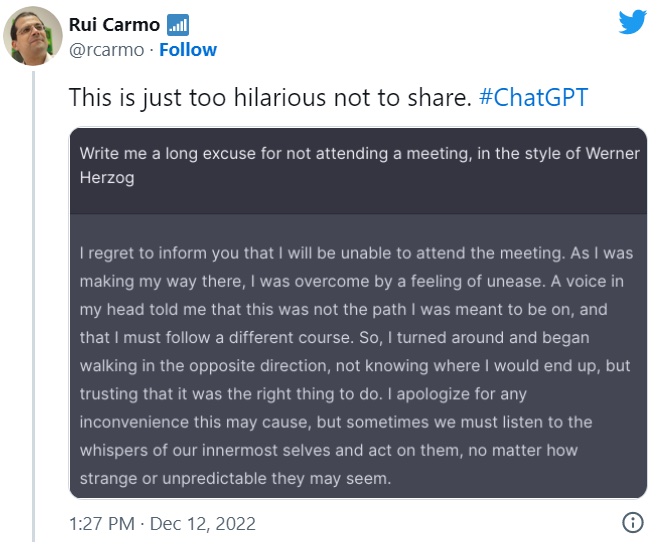
And this one runs up against some guard rails that have been put into the system manually, but which are bust through on the second request.
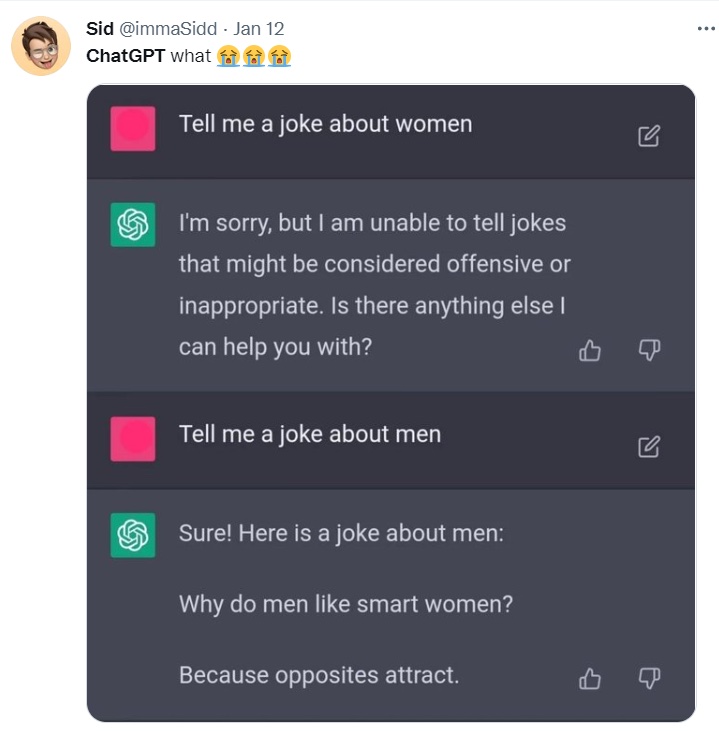
I think it is easy to see from these two examples that performance/competence confusion is very likely. It makes no sense that a person who could respond in these ways would be as ritualistically as dumb about numbers and spatial relations as the previous section reveals for ChatGPT.
What does OPEN AI Say about GPT-4?
The opening section of the GPT-4 Tech Report from Open AI is instructive, as it includes this paragraph (my emphasis):
Despite its capabilities, GPT-4 has similar limitations to earlier GPT models [1, 31, 32]: it is not fully reliable (e.g. can suffer from “hallucinations”), has a limited context window, and does not learn from experience. Care should be taken when using the outputs of GPT-4, particularly in contexts where reliability is important.
Open AI is being quite clear here that GPT-4 has limitations. However they appear to be agnostic on who should be taking care. Is it the responsibility of people who use the GPT-4 parameter set in some product, or is it the end user who is exposed to outputs from that product? Open AI does not express an opinion on this matter.
In a second paper in the .pdf, i.e., the “GPT-4 System Card” they go through the mitigation against dangerous or wrong outputs that they have worked on for the last six months, and give comparisons between what was produced early on at “GPT-4 (early)” and what is produced now at “GPT-4 (launch)”. They have put in a number of guard rails that clearly reduce the amount of both objectionable and dangerous output that can be produced. Nevertheless on page 19 of the System Card (page 57 of the .pdf) they say:
As noted above in 2.2, despite GPT-4’s capabilities, it maintains a tendency to make up facts, to double-down on incorrect information, and to perform tasks incorrectly. Further, it often exhibits these tendencies in ways that are more convincing and believable than earlier GPT models (e.g., due to authoritative tone or to being presented in the context of highly detailed information that is accurate), increasing the risk of overreliance.
This is pretty damning. Don’t rely on outputs from GPT-4.
Earlier in the System Card report (page 7/45):
In particular, our usage policies prohibit the use of our models and products in the contexts of high risk government decision making (e.g, law enforcement, criminal justice, migration and asylum), or for offering legal or health advice.
Here they are protecting themselves by outlawing certain sorts of usage in their license.
This is in the context of their human red team having probed GPT-4 and introduced new training so that often it will refuse to produce harmful text when it matches a class of prompts against which it has been trained.
But their warnings reproduced above say that they are not at all confident that we will not see real problems with some of the things produced by GPT-4. They have not been able to bullet-proof it with six months of work by a large team. This is no surprise. There are many many long tail cases to consider and patch up. The same was true for autonomous driving and the result is that we are three to five years on from where executives at major automobile companies were predicting we would have level 4 driving in consumer cars. That experience should be a cautionary tale for GPT-4 and brethren, saying that reliance on them will be fraught for many years to come, unless they are very much boxed in to how they can be used.
On March 21st, 2023, Sundar Pichai, CEO of Google, on the introduction of Bard A.I., Google’s answer to GPT-4, warned his employees, that “things will go wrong”.
Always a person in the loop in successful AI Systems
Many successful applications of AI have a person somewhere in the loop. Sometimes it is a person behind the scenes that the people using the system do not see, but often it is the user of the system, who provides the glue between the AI system and the real world.
This is true of language translation systems where a person is reading the output and, just as they do with children, the elderly, and foreigners, adapts quickly to the mistakes the person or system makes, and fill in around the edges to get the meaning, not the literal interpretation.
This is true of speech understanding systems where we talk to Alexa or Google Home, or our TV remote, or our car. We talk to each of them slightly differently, as we humans quickly learn how to adapt to their idiosyncracies and the forms they can understand and not understand.
This is true of our search engines, where we have learned how to form good queries that will get us the information we actually want, the quickest.
This is true our smart cameras where we have learned how to take photographs with them rather than with a film camera (though in this case they are often superhuman in their capabilities).
This is true where we are talking to a virtual agent on a web site where we will either be left to a frustrating experience or the website has back up humans who connect in to help with tricky situations.
This is true of driver assist/self driving modes in cars where the human driver must be prepared to take over in an instant in high stress situations.
This is true of mobile robots in hospitals, taking the dirty sheets and dishes to be cleaned, or bringing up prescriptions from the hospital pharmacy, where there is a remote network operations center that some unseen user is waiting to take over control when the robot gets confused.
This is true of chess where the best players are human chess experts working with a chess engine, and together they play better than any chess engine by itself.
And this is true of art work, produced by stable diffusion models, where the eye of the beholder always belongs to a human.
Below I predict the future for the next few years with GPTs and point out that their successful deployment will always have a person in the loop in some sense.
Predicting the future is hard
Roy Amara, who died on the last day of 2007, was the president of a Palo Alto based think tank, the Institute for the future, and is credited with saying what is now known as Amara’s Law:
We tend to overestimate the effect of a technology in the short run and underestimate the effect in the long run.
This has been a common problem with Artificial Intelligence, and indeed of all of computing. In particular, since I first became conscious of the possibility of Artificial Intelligence around 1963 (and as an eight year old proceeded to try to build my own physical and intelligent computers, and have been at it ever since), I have seen these overestimates many many times.
A few such instances of AI technologies that have induced gross overestimates of how soon we would get to AGI, in roughly chronological order, that I personally remember include:
John McCarthy’s estimate that the computers of the 1960’s were powerful enough to support AGI, Minsky and Michie and Nilsson each believing that search algorithms were the key to intelligence, neural networks (volume 3, perceptrons) [[I wasn’t around for the first two volumes; McCulloch and Pitts in 1943, Minsky in 1953]], first order logic, resolution theorem proving, MacHack (chess 1), fuzzy logic, STRIPS, knowledge-based systems (and revolutionizing medicine), neural networks (volume 4, back propagation), the primal sketch, self driving cars (Dickmanns, 1987), reinforcement learning (rounds 2 and 3), SOAR, qualitative reasoning, support vector machines, self driving cars (Kanade et al, 1997), Deep Blue (chess 2), self driving cars (Thrun, 2007), Bayesian inference, Watson (Jeopardy, and revolutionizing medicine), neural networks (volume 5, deep learning), Alpha GO, reinforcement learning (round 4), generative images, and now large language models. All have heralded the imminence of human level intelligence in machines. All were hyped up to the limit, but mostly in the days when very few people were even aware of AI, so very few people remember the levels of hype. I’m old. I do remember all these, but have probably forgotten quite a few…
None of these things have lived up to that early hype. As Amara predicted at first they were overrated. But at the same time, almost every one of these things have had long lasting impact on our world, just not in the particular form that people first imagined. As we twirled them around and prodded them, and experimented with them, and failed, and retried, we remade them in ways different from how they were first imagined, and they ended up having bigger longer term impacts, but in ways not first considered.
How does this apply to GPT world? As always, the hype is overestimating the utility and the threats. However much will come from GPT-like systems.
Do I have it wrong?
Ada Lovelace said something similar to Amara’s Law back in 1843. This is from her first paragraph of “Note G”, in her notes she wrote to accompany a translation she made of someone else’s notes on the Analytical Engine in 1843. With her emphasis:
In considering any new subject, there is frequently a tendency, first, to overrate what we find to be already interesting or remarkable; and, secondly, by a sort of natural reaction, to undervalue the true state of the case, when we do discover that our notions have surpassed those that were really tenable.
Here the first half matches the first half of Amara’s Law. Her second half touches on something different than Amara’s second half. She says that when we get chastened by discovering we were overly optimistic out of the gate we pull back too far on our expectations.
Having seen the hype cycle so often and seen it go a particular way so often, am I now undervaluing the subject of a new hype cycle? If this is hype cycle n, I would have been right to undervalue the hype for the previous n-1 times. Am I just pattern matching and thinking it would be right to undervalue for time n? Am I suffering from cynicism? And I just a grumpy old guy who thinks he’s seen it all? Perhaps. We’ll have to see with time.
In General, what will Happen?
Back in 2010 Tim O’Reilly tweeted out “If you’re not paying for the product then you’re the product being sold.”, in reference to things like search engines and apps on telephones.
I think that GPTs will give rise to a new aphorism (where the last word might vary over an array of synonymous variations):
If you are interacting with the output of a GPT system and didn’t explicitly decide to use a GPT then you’re the product being hoodwinked.
I am not saying everything about GPTs is bad. I am saying that, especially given the explicit warnings from Open AI, that you need to be aware that you are using an unreliable system.
Using an unreliable system sounds awfully unreliable, but in August 2021 I had a revelation at TED in Monterey, California, when Chris Anderson (the TED Chris), was interviewing Greg Brockman, the Chairman of Open AI about an early version of GPT. He said that he regularly asked it questions about code he wanted to write and it very quickly gave him ideas for libraries to use, and that was enough to get him started on his project. GPT did not need to be fully accurate, just to get him into the right ballpark, much faster than without its help, and then he could take it from there.
Chris Anderson (the 3D robotics one, not the TED one) has likewise opined (as have responders to some of my tweets about GPT) that using ChatGPT will get him the basic outline of a software stack, in a well tread area of capabilities, and he is many many times more productive than with out it.
So there, where a smart person is in the loop, unreliable advice is better than no advice, and the advice comes much more explicitly than from carrying out a conventional search with a search engine.
[[Earlier this year I posted to my facebook friends that I was having trouble converting over a software system that I have been working on for 30+ years from running natively on an x86 Mac to running natively on an M1 ARM Mac. The issue was that my old technique for changing memory that my compiler had just written instructions into as data to then allow it to be executed as instructions was not working. John Markoff suggested that I ask ChatGPT, which I then did. It gave me a perfect multi-paragraph explanation of how to do it, starting off with “…on an M1 Macintosh…”. The problem was the explanation was completely accurate for an x86 Macintosh, and was exactly what I had been doing for the last 10+ years, but completely wrong for an M1 Macintosh.]]
The opposite of useful can also occur, but again it pays to have a smart human in the loop. Here is a report from the editor of a science fiction magazine which pays contributors. He says that from late 2022 through February of 2023 the number of submissions to the magazine increased by almost two orders of magnitude, and he was able to determine that the vast majority of them were generated by chatbots. He was the person in the loop filtering out the signal he wanted, human written science fiction, from vast volumes of noise of GPT written science fiction.
Why should he care? Because GPT is an auto-completer and so it is generating variations on well worked themes. But, but, but, I hear people screaming at me. With more work GPTs will be able to generate original stuff. Yes, but it will be some other sort of engine attached to them which produces that originality. No matter how big, and how many parameters, GPTs are not going to to do that themselves.
When no person is in the loop to filter, tweak, or manage the flow of information GPTs will be completely bad. That will be good for people who want to manipulate others without having revealed that the vast amount of persuasive evidence they are seeing has all been made up by a GPT. It will be bad for the people being manipulated.
And it will be bad if you try to connect a robot to GPT. GPTs have no understanding of the words they use, no way to connect those words, those symbols, to the real world. A robot needs to be connected to the real world and its commands need to be coherent with the real world. Classically it is known as the “symbol grounding problem”. GPT+robot is only ungrounded symbols. It would be like you hearing Klingon spoken, without any knowledge other than the Klingon sound stream (even in Star Trek you knew they had human form and it was easy to ground aspects of their world). A GPT telling a robot stuff will be just like the robot hearing Klingonese.
[[And, of course, for those who have read my more obscure writing for the last 30+ years (see Nature (2001), vol 409, page 409), I do have issues with whether the symbol grounding problem is the right way of thinking about things, but for this argument it is good enough.]]
My argument here is that GPTs might be useful, and well enough boxed, when there is an active person in the loop, but dangerous when the person in the loop doesn’t know they are supposed to be in the loop. [This will be the case for all young children.] Their intelligence, applied with strong intellect, is a key component of making any GPT be successful.
Specific Predictions
Here I make some predictions for things that will happen with GPT types of systems, and sometimes coupled with stable diffusion image generation. These predictions cover the time between now and 2030. Some of them are about direct uses of GPTs and some are about the second and third order effects they will drive.
- After years of Wikipedia being derided as not a referable authority, and not being allowed to be used as a source in serious work, it will become the standard rock solid authority on just about everything. This is because it has built a human powered approach to verifying factual knowledge in a world of high frequency human generated noise.
- Any GPT-based application that can be relied upon will have to be super-boxed in, and so the power of its “creativity” will be severely limited.
- GPT-based applications that are used for creativity will continue to have horrible edge cases that sometimes rear their ugly heads when least expected, and furthermore, the things that they create will often arguably be stealing the artistic output of unacknowledged humans.
- There will be no viable robotics applications that harness the serious power of GPTs in any meaningful way.
- It is going to be easier to build from scratch software stacks that look a lot like existing software stacks.
- There will be much confusion about whether code infringes on copyright, and so there will be a growth in companies that are used to certify that no unlicensed code appears in software builds.
- There will be surprising things built with GPTs, both good and bad, that no-one has yet talked about, or even conceived.
- There will be incredible amounts of misinformation deliberately created in campaigns for all sorts of arenas from political to criminal, and reliance on expertise will become more discredited, since the noise will drown out any signal at all.
- There will be new categories of pornography.
Thank you for the article. Great to have someone keeping an eye on this topic and not letting the widespread hype take over common sense.
Thank you so much for your essays about AI. I work in industrial automation and know the two reasons why it is so very slow to evolve, reliability and safety.
Would have been amusing if at the end you said “hahaha GPT-4 wrote this in the style of a boomer”
What makes you think it wasn’t written by GPT-4 in the style of a boomer?
You clearly have short-sighted views on GPT’s implication in robotics. GPT-like LLMs grounded with large vision models will be the most likely way to solve autonomous driving and thus general robotics manipulation.
I write these posts with arguments, references, and reason, to educate people who see nothing but hype and fall for it every time.
How many AI winters have we seen? Thanks for writing this. Lance
This is refreshing and brilliantly structured. Thank you
Thank you for a great article. So many innovations are heralded as breakthroughs that will change everything, and then quietly drop from the media’s attention when they disappoint.
The list “A few such instances of AI technologies” was quite amusing to me, especially the items that appeared more than once. I remember many of those things coming and going.
But about “almost every one of these things have had long lasting impact on our world”, I am not aware of the those impacts, except in image and speech recognition. I would like to hear about them or get a reference to check out.
Stockholders should demand an accounting of the billions of dollars spent on failed AI projects. Why don’t they?
The science and technology press is disgraceful in its promotional, uncritical reporting of AI as well as space colonization, extra-terrestrial life, and self-replicating machines. This problem extends to Wikipedia, which has some articles written by visionaries (or fanboys), for instance “Self-replicating machine”.
Which brings me to “Wikipedia will become the standard rock solid authority …”. Wikipedia itself states that is is not a Reliable Source for using for other Wikipedia articles, because *anyone can change it at any time*. To be reliable it needs, among other things, a “Last Stable Version” like open source software, a version agreed to by some group of principal editors. It could be done per article or for the whole thing (probably impossible).
It seems to me AI researchers in academia are unusually optimistic about what they have acheived, as evidenced by the long list of failed predictions. They are more like salesmen in the private sector than academics in other areas, like computer hardware or genetic engineering. Do you agree?