

Past is prologue1.
I mean that both the ways people interpret Shakespeare’s meaning when he has Antonio utter the phrase in The Tempest.
In one interpretation it is that the past has predetermined the sequence which is about to unfold–and so I believe that how we have gotten to where we are in Artificial Intelligence will determine the directions we take next–so it is worth studying that past.
Another interpretation is that really the past was not much and the majority of necessary work lies ahead–that too, I believe. We have hardly even gotten started on Artificial Intelligence and there is lots of hard work ahead.
THE EARLY DAYS
It is generally agreed that John McCarthy coined the phrase “artificial intelligence” in the written proposal2 for a 1956 Dartmouth workshop, dated August 31st, 1955. It is authored by, in listed order, John McCarthy of Dartmouth, Marvin Minsky of Harvard, Nathaniel Rochester of IBM and Claude Shannon of Bell Laboratories. Later all but Rochester would serve on the faculty at MIT, although by early in the sixties McCarthy had left to join Stanford University. The nineteen page proposal has a title page and an introductory six pages (1 through 5a), followed by individually authored sections on proposed research by the four authors. It is presumed that McCarthy wrote those first six pages which include a budget to be provided by the Rockefeller Foundation to cover 10 researchers.
The title page says A PROPOSAL FOR THE DARTMOUTH SUMMER RESEARCH PROJECT ON ARTIFICIAL INTELLIGENCE. The first paragraph includes a sentence referencing “intelligence”:
The study is to proceed on the basis of the conjecture that every aspect of learning or any other feature of intelligence can in principle be so precisely described that a machine can be made to simulate it.
And then the first sentence of the second paragraph starts out:
The following are some aspects of the artificial intelligence problem:
That’s it! No description of what human intelligence is, no argument about whether or not machines can do it (i.e., “do intelligence”), and no fanfare on the introduction of the term “artificial intelligence” (all lower case).
In the linked file above there are an additional four pages dated March 6th, 1956, by Allen Newell and Herb Simon, at that time at the RAND Corporation and Carnegie Institute of Technology respectively (later both were giants at Carnegie Mellon University), on their proposed research contribution. They say that they are engaged in a series of forays into the area of complex information processing, and that a “large part of this activity comes under the heading of artificial intelligence”. It seems that the phrase “artificial intelligence” was easily and quickly adopted without any formal definition of what it might be.
In McCarthy’s introduction, and in the outlines of what the six named participants intend to research there is no lack of ambition.
The speeds and memory capacities of present computers may be insufficient to simulate many of the higher functions of the human brain, but the major obstacle is not lack of machine capacity, but our inability to write programs taking full advantage of what we have.
Some of the AI topics that McCarthy outlines in the introduction are how to get a computer to use human language, how to arrange “neuron nets” (they had been invented in 1943–a little while before today’s technology elite first heard about them and started getting over-excited) so that they can form concepts, how a machine can improve itself (i.e., learn or evolve), how machines could form abstractions from using its sensors to observe the world, and how to make computers think creatively. These topics are expanded upon in the individual work proposals by Shannon, Minsky, Rochester, and McCarthy. The addendum from Newell and Simon adds to the mix getting machines to play chess (including through learning), and prove mathematical theorems, along with developing theories on how machines might learn, and how they might solve problems similar to problems that humans can solve.
No lack of ambition! And recall that at this time there were only a handful of digital computers in the world, and none of them had more than at most a few tens of kilobytes of memory for running programs and data, and only punched cards or paper tape for long term storage.
McCarthy was certainly not the first person to talk about machines and “intelligence”, and in fact Alan Turing had written and published about it before this, but without the moniker of “artificial intelligence”. His best known foray is Computing Machinery and Intelligence3 which was published in October 1950. This is the paper where he introduces the “Imitation Game”, which has come to be called the “Turing Test”, where a person is to decide whether the entity they are conversing with via a 1950 version of instant messaging is a person or a computer. Turing estimates that in the year 2000 a computer with 128MB of memory (he states it as  binary digits) will have a 70% chance of fooling a person.
binary digits) will have a 70% chance of fooling a person.
Although the title of the paper has the word “Intelligence” in it, there is only one place where that word is used in the body of the paper (whereas “machine” appears at least 207 times), and that is to refer to the intelligence of a human who is trying to build a machine that can imitate an adult human. His aim however is clear. He believes that it will be possible to make a machine that can think as well as a human, and by the year 2000. He even estimates how many programmers will be needed (sixty is his answer, working for fifty years, so only 3,000 programmer years–a tiny number by the standards of many software systems today).
In a slightly earlier 1948 paper titled Intelligent Machinery but not published4 until 1970, long after his death, Turing outlined the nature of “discrete controlling machines”, what we would today call “computers”, as he had essentially invented digital computers in a paper he had written in 1937. He then turns to making a a machine that fully imitates a person, even as he reasons, the brain part might be too big to be contained within the locomoting sensing part of the machine, and instead must operate it remotely. He points out that the sensors and motor systems of the day might not be up to it, so concludes that to begin with the parts of intelligence that may be best to investigate are games and cryptography, and to a less extent translation of languages and mathematics.
Again, no lack of ambition, but a bowing to the technological realities of the day.
When AI got started the clear inspiration was human level performance and human level intelligence. I think that goal has been what attracted most researchers into the field for the first sixty years. The fact that we do not have anything close to succeeding at those aspirations says not that researchers have not worked hard or have not been brilliant. It says that it is a very hard goal.
I wrote a (long) paper Intelligence without Reason5 about the pre-history and early days of Artificial Intelligence in 1991, twenty seven years ago, and thirty five years into the endeavor. My current blog posts are trying to fill in details and to provide an update for a new generation to understand just what a long term project this is. To many it all seems so shiny and exciting and new. Of those, it is exciting only.
TOWARDS TODAY
In the early days of AI there were very few ways to connect sensors to digital computers or to let those computers control actuators in the world.
In the early 1960’s people wanting to work on computer vision algorithms had to take photographs on film, turn them into prints, attach the prints to a drum, then have that drum rotate and move up and down next to a single light brightness sensor to turn the photo into an array of intensities. By the late seventies, with twenty or thirty pounds of equipment, costing tens of thousands of dollars, a researcher could get a digital image directly from a camera into a computer. Things did not become simple-ish until the eighties and they have gotten progressively simply and cheaper over time.
Similar stories hold for every other sensor modality, and also for output–turning results of computer programs into physical actions in the world.
Thus, as Turing had reasoned, early work in Artificial Intelligence turned towards domains where there was little need for sensing or action. There was work on games, where human moves could easily be input and output to and from a computer via a keyboard and a printer, mathematical exercises such as calculus applied to symbolic algebra, or theorem proving in logic, and to understanding typed English sentences that were arithmetic word problems.
Writing programs that could play games quickly lead to the idea of “tree search” which was key to almost all of the early AI experiments in the other fields listed above, and indeed, is now a basic tool of much of computer science. Playing games early on also provided opportunities to explore Machine Learning and to invent a particular variant of it, Reinforcement Learning, which was at the heart of the recent success of the AlphaGo program. I described this early history in more detail in my August 2017 post Machine Learning Explained.
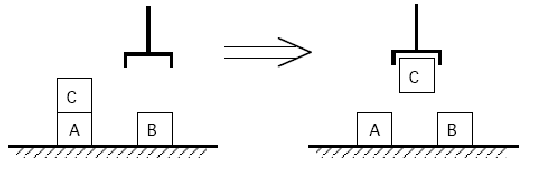
Before too long a domain known as blocks world was invented where all sorts of problems in intelligence could be explored. Perhaps the first PhD thesis on computer vision, by Larry Roberts at MIT in 1963, had shown that with a carefully lighted scene, all the edges of wooden block with planar surfaces could be recovered.

That validated the idea that it was OK to work on complex problems with blocks where the description of their location or their edges was the input to the program, as in principle the perception part of the problem could be solved. This then was a simulated world of perception and action, and it was the principal test bed for AI for decades.
Some people worked on problem solving in a two dimensional blocks world with an imagined robot that could pick up and put down blocks from the top of a stack, or on a simulated one dimensional table.
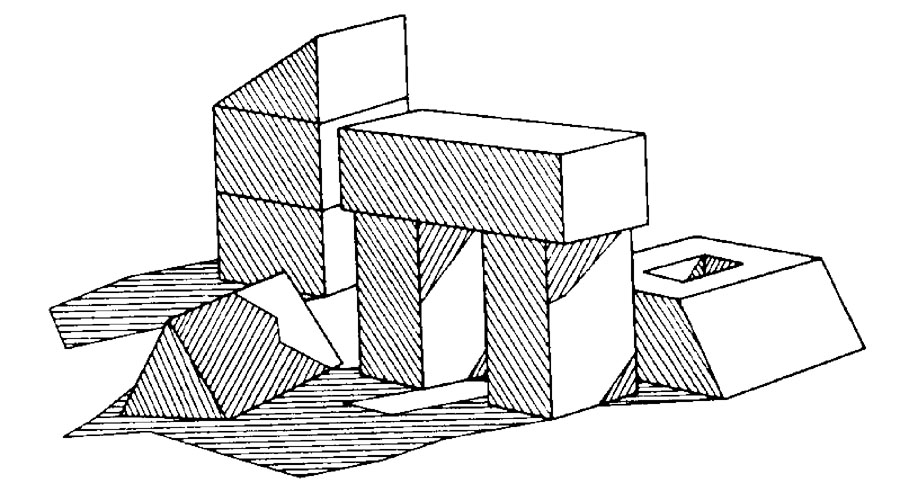
Others worked on recovering the geometry of the underlying three dimensional blocks from just the input lines, including with shadows, paving the way for future more complete vision systems than Roberts had demonstrated.
And yet others worked on complex natural language understanding, and all sorts of problem solving in worlds with complex three dimensional blocks.
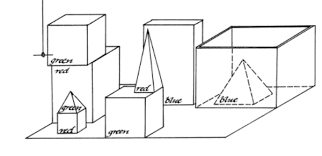
No one worked in these blocks worlds because that was their ambition. Rather they worked in them because with the tools they had available they felt that they could make progress on problems that would be important for human level intelligence. At the same time they did not think that was just around the corner, one magic breakthrough away from all being understood, implemented, and deployed.
Over time may sub-disciplines in AI developed as people got deeper and deeper into the approaches to particular sub-problems that they had discovered. Before long there was enough new work coming out that no-one could keep up with the breadth of AI research. The names of the sub-disciplines included planning, problem solving, knowledge representation, natural language processing, search, game playing, expert systems, neural networks, machine inference, statistical machine learning, robotics, mobile robotics, simultaneous localization and mapping, computer vision, image understanding, and many others.
Breakoff Groups
Often, as a group of researchers found a common set of problems to work on they would break off from the mainstream and set up their own journals and conferences where reviewing of papers could all be done by people who understood the history and context of the particular problems.
I was involved in two such break off groups in the late 1980’s and early 1990’s, both of which still exist today; Artificial Life, and Simulation of Adaptive Behavior. The first of these looks at fundamental mechanisms of order from disorder and includes evolutionary processes. The second looks at how animal behaviors can be generated by the interaction of perception, action, and computation. Both of these groups and their journals are still active today.
Below is my complete set of the Artificial Life journal from when it was published on paper from 1993 through to 2014. It is still published online today, by the MIT Press.

There were other journals on Artificial Life, and since 1989 there have been international conferences on it. I ran the 1994 conference and there were many hundreds of participants and there were 56 carefully reviewed papers published in hard copy proceedings which I co-edited with Pattie Maes; all those papers are now available online.
And here is my collection of the Adaptive Behavior journal from when it was published on paper from 1992 through to 2013. It is still published online today, by Sage.

And there has always been a robust series of major conferences, called SAB, for Simulation of Adaptive Behavior with paper and now online proceedings.
The Artificial Life Conference will be in Tokyo this year in July, and the SAB conference will be in Frankfurt in August. Each will attract hundreds of researchers. And the 20+ volumes of each of the journals above have 4 issues each, so close to 100 issues, with 4 to 10 papers each, so many hundreds of papers in the journal series. These communities are vibrant and the Artificial Life community has had some engineering impact in developing genetic algorithms which are in use in some number of application.
But neither the Artificial Life community nor the Simulation of Adaptive Behavior community have succeeded at their early goals.
We still do not know how living systems arise from non-living systems, and in fact still do not have good definitions of what life really is. We do not have generally available evolutionary simulations which let us computationally evolve better and better systems, despite the early promise when we first tried it. And we have not figured out how to evolve systems that have even the rudimentary components of a complete general intelligence, even for very simple creatures.
On the SAB side we can still not computationally simulate the behavior of the simplest creature that has been studied at length. That is the tiny worm C. elegans, which has 959 cells total of which 302 are neurons. We know its complete connectome (and even its 56 glial cells), but still we can’t simulate how they produce much of its behaviors.
I tell these particular stories not because they were uniquely special, but because they give an idea of how research in hard problems works, especially in academia. There were many, many (at least twenty or thirty) other AI subgroups with equally specialized domains that split off. They sometimes flourished and sometimes died off. All those subgroups gave themselves unique names, but were significant in size, in numbers of researchers and in active sharing and publication of ideas.
But all researchers in AI were, ultimately, interested in full scale general human intelligence. Often their particular results might seem narrow, and in application to real world problems were very narrow. But general intelligence has always been the goal.
I will finish this section with a story of a larger scale specialized research group, that of computer vision. That specialization has had real engineering impact. It has had four or more major conferences per year for thirty five plus years. It has half a dozen major journals. I cofounded one of them in 1987, with Takeo Kanade, the International Journal of Computer Vision, which has had 126 volumes (I only stayed as an editor for the first seven volumes) and 350 issues since then, with 2,080 individual articles. Remember, that is just one of the half dozen major journals in the field. The computer vision community is what a real large push looks like. This has been a sustained community of thousands of researchers world wide for decades.
CATCHY NAMES
I think the press, and those outside of the field have recently gotten confused by one particular spin off name, that calls itself AGI, or Artificial General Intelligence. And the really tricky part is that there a bunch of completely separate spin off groups that all call themselves AGI, but as far as I can see really have very little commonality of approach or measures of progress. This has gotten the press and people outside of AI very confused, thinking there is just now some real push for human level Artificial Intelligence, that did not exist before. They then get confused that if people are newly working on this goal then surely we are about to see new astounding progress. The bug in this line of thinking is that thousands of AI researchers have been working on this problem for 62 years. We are not at any sudden inflection point.
There is a journal of AGI, which you can find here. Since 2009 there have been a total of 14 issues, many with only a single paper, and only 47 papers in total over that ten year period. Some of the papers are predictions about AGI, but most are very theoretical, modest, papers about specific logical problems, or architectures for action selection. None talk about systems that have been built that display intelligence in any meaningful way.
There is also an annual conference for this disparate group, since 2008, with about 20 papers, plus or minus, per year, just a handful of which are online, at the authors’ own web sites. Again the papers range from risks of AGI to very theoretical specialized, and obscure, research topics. None of them are close to any sort of engineering.
So while there is an AGI community it is very small and not at all working on any sort of engineering issues that would result in any actual Artificial General Intelligence in the sense that the press means when it talks about AGI.
I dug a little deeper and looked at two groups that often get referenced by the press in talking about AGI.
One group, perhaps the most referenced group by the press, styles themselves as an East San Francisco Bay Research Institute working on the mathematics of making AGI safe for humans. Making safe human level intelligence is exactly the goal of almost all AI researchers. But most of them are sanguine enough to understand that that goal is a long way off.
This particular research group lists all their publications and conference presentations from 2001 through 2018 on their web site. This is admirable, and is a practice followed by most research groups in academia.
Since 2001 they have produced 10 archival journal papers (but see below), made 29 presentations at conferences, written 9 book chapters, and have 45 additional internal reports, for a total output of 93 things–about what one would expect from a single middle of the pack professor, plus students, at a research university. But 36 of those 93 outputs are simply predictions of when AGI will be “achieved”, so cut it down to 57 technical outputs, and then look at their content. All of them are very theoretical mathematical and logical arguments about representation and reasoning, with no practical algorithms, and no applications to the real world. Nothing they have produced in 18 years has been taken up and used by any one else in any application of demonstration any where.
And the 10 archival journal papers, the only ones that have a chance of being read by more than a handful of people? Every single one of them is about predicting when AGI will be achieved.
This particular group gets cited by the press and by AGI alarmists again and again. But when you look there with any sort of critical eye, you find they are not a major source of progress towards AGI.
Another group that often gets cited as a source for AGI, is a company in Eastern Europe that claims it will produce an Artificial General Intelligence within 10 years. It is only a company in the sense that one successful entrepreneur is plowing enough money into it to sustain it. Again let’s look at what its own web site tells us.
In this case they have been calling for proposals and ideas from outsiders, and they have distilled that input into the following aspiration for what they will do:
We plan to implement all these requirements into one universal algorithm that will be able to successfully learn all designed and derived abilities just by interacting with the environment and with a teacher.
Yeah, well, that is just what Turing suggested in 1948. So this group has exactly the same aspiration that has been around for seventy years. And they admit it is their aspiration but so far they have no idea of how to actually do it. Turing, in 1948, at least had a few suggestions.
If you, as a journalist, or a commentator on AI, think that the AGI movement is large and vibrant and about to burst onto the scene with any engineered systems, you are confused. You are really, really confused.
Journalists, and general purpose prognosticators, please, please, do your homework. Look below the surface and get some real evaluation on whether groups that use the phrase AGI in their self descriptions are going to bring you human level Artificial Intelligence, or indeed whether they are making any measurable progress towards doing so. It is tempting to see the ones out on the extreme, who don’t have academic appointments, working valiantly, and telling stories of how they are different and will come up something new and unique, as the brilliant misfits. But in all probability they will not succeed in decades, just as the Artificial Life and the Simulation of Adaptive Behavior groups that I was part of have still not succeeded in their goals of almost thirty years ago.
Just because someone says they are working on AGI, Artificial General Intelligence, that does not mean they know how to build it, how long it might take, or necessarily be making any progress at all. These lacks have been the historical norm. Certainly the founding researchers in Artificial Intelligence in the 1950’s and 1960’s thought that they were working on key components of general intelligence. But that does not mean they got close to their goal, even when they thought it was not so very far off.
So, journalists, don’t you dare, don’t you dare, come back to me in ten years and say where is that Artificial General Intelligence that we were promised? It isn’t coming any time soon.
And while we are on catchy names, let’s not forget “deep learning”. I suspect that the word “deep” in that name leads outsiders a little astray. Somehow it suggests that there is perhaps a deep level of understanding that a “deep learning” algorithm has when it learns something. In fact the learning is very shallow in that sense, and not at all what “deep” refers to. The “deep” in “deep learning” refers to the number of layers of units or “neurons” in the network.
When back propagation, the actual learning mechanism used in deep learning, was developed in the 1980’s most networks had only two or three layers. The revolutionary new networks are the same in structure as 30 years ago but have as many as 12 layers. That is what the “deep” is about, 12 versus 3. In order to make learning work on these “deep” networks there had to be lots more computer power (Moore’s Law took care of that over 30 years), a clever change to the activation function in each neuron, and a way to train the network in stages known as clamping. But not deep understanding.
WHY THIS ESSAY?
Why did I post this? I want to clear up some confusions about Artificial Intelligence, and the goals of people who do research in AI.
There have certainly been a million person-years of AI research carried out since 1956 (much more than the three thousand that Alan Turing thought it would take!), with an even larger number of person-years applied to AI development and deployment.
We are way off the early aspirations of how far along we would be in Artificial Intelligence by now, or by the year 2000 or the year 2001. We are not close to figuring it out. In my next blog post, hopefully in May of 2018 I will outline all the things we do not understand yet about how to build a full scale artificially intelligent entity.
My intent of that coming blog post is to:
- Stop people worrying about imminent super intelligent AI (yet, I know, they will enjoy the guilty tingly feeling thinking about it, and will continue to irrationally hype it up…).
- To suggest directions of research which can have real impact on the future of AI, and accelerate it.
- To show just how much fun research remains to be done, and so to encourage people to work on the hard problems, and not just the flashy demos that are hype bait.
In closing, I would like to share Alan Turing’s last sentence from his paper “Computing Machinery and Intelligence”, just as valid today as it was 68 years ago:
We can only see a short distance ahead, but we can see plenty there that needs to be done.
1This whole post started out as a footnote to one of the two long essays in the FoR&AI series that I am working on. It clearly got too long to be a footnote, but is much somewhat shorter than my usual long essays.
2I have started collecting copies of hard to find historical documents and movies about AI in one place, as I find them in obscure nooks of the Web, where the links may change as someone reorganizes their personal page, or on a course page. Of course I can not guarantee that this link will work forever, but I will try to maintain it for as long as I am able. My web address has been stable for almost a decade and a half already.
3This version is the original full version as it appeared in the journal Mind, including the references. Most of the versions that can be found on the Web are a later re-typesetting without references and with a figure deleted–and I have not fully checked them for errors that might have been introduced–I have noticed at least one place were  has been substituted for . That is why I have tracked down the original version to share here.
has been substituted for . That is why I have tracked down the original version to share here.
4His boss at the National Physical Laboratory (NPL), Sir Charles Darwin, grandson of that Charles Darwin, did not approve of what he had written, and so the report was not allowed to be published. When it finally appeared in 1970 it was labelled as the “prologue” to the fifth volume of an annual series of volumes titled “Machine Intelligence”, produced in Britain, and in this case edited by Bernard Meltzer and Donald Michie, the latter a war time colleague of Turing at Bletchley Park. They too, used the past as prologue.
5This paper was written on the occasion of my being co-winner (with Martha Pollack, now President of Cornell University) in 1991 of the Computers and Thought award that is given at the bi-annual International Joint Conference on Artificial Intelligence (IJCAI) to a young researcher. There was some controversy over whether at age 36 I was still considered young and so the rules were subsequently tightened up in a way that guarantees that I will forever be the oldest recipient of this award. In any case I had been at odds with the conventional AI world for some time (I seem to remember a phrase including “angry young man”…) so I was very grateful to receive the award. The proceedings of the conference had a six page, double column, limit on contributed papers. As a winner of the award I was invited to contribute a paper with a relaxed page limit. I took them at their word and produced a paper which spanned twenty seven pages and was over 25,000 words long! It was my attempt at a scholarly deconstruction of the field of AI, along with the path forward as I saw it.
Another great essay!
Let me be the first to point out that the deep nets have gotten much deeper than 12 layers. Some (https://github.com/KaimingHe/resnet-1k-layers) have more than 1000 layers now. They are trained without clamping.
Yikes. 1,000 layers. 1,000,000 here we come! Thanks for the update Tom.
Operationally I know of Deepnets >1,200 layers. Assume the top firms are pushing my further in testing.
The neocortex has no more than 20 layers. And yet, unlike deep neural nets, the brain can instantly see new complex objects or patterns that it has never seen before. Most deep learning researchers do not realize that that there are not enough neurons and synapses in the brain to model all the possible patterns it sees in a lifetime. Not even close. And yet we can see them all.
AI must go through a complete paradigm shift before human-like intelligence can be achieved.
And that paradigm shift should include “synchronized oscillations”, the ultimate processing tool in the human brain.
I don’t approve comments that are advertising erectile dysfunction drugs (the vast majority) or those where someone is peddling their own “solution” for AI. I checked and it looks like “synchronized oscillations” are something that you peddle as a research topic, so I will approve this post. BUT, it is far from clear that it is anything like a causative phenomenon in the brain, and I have never seen anyone with any convincing argument how it could be causative. It may simply be a consequence of other things.
See this paper http://journals.plos.org/ploscompbiol/article?id=10.1371/journal.pcbi.1005268 for some insight into how badly it may be that we understand anything about correlations and causation of neural spikes in brains.
If this is blog post is an elaboration of a footnote – more please. You help put AlphGo in context and debates regarding the legal status of Machines.
Nice essay!
As Tom pointed out, people are playing with deep network with 1k layers, but more importantly, networks with around 100 layers are used routinely in large-scale commercial applications.
It’s hard to explain to non-specialists that AGI is not a “thing”, and that most venues that have AGI in their name deal in highly speculative and theoretical issues that sometimes flirt with charming naïveté, self-delusion, crackpottery, even charlatanism.
There is a thin domain of research that, while having ambitious goals of making progress towards human-level intelligence, is also sufficiently grounded in science and engineering methodologies to bring real progress in technology. That’s the sweet spot.
I liked this essay very much. But a comment on one point: I have seen the term “AGI” used not only by fringe groups but also by several mainstream, high profile people (e.g., Demis Hassabis) to describe their research. I’m not sure which “East San Francisco Bay Research Institute” you’re referring to — I don’t think it’s OpenAI, since they haven’t been around since 2001, but OpenAI’s web page “About” statement has the first line, “OpenAI’s mission is to build safe AGI,”. So it’s not clear at all what the “AGI Community” refers to. No wonder journalists are confused.
I’m glad you mentioned ALife — even though the field hasn’t achieved its lofty goals, the conferences were sure fun!
Thank you for a very interesting (and topical) essay! It clearly outlines the research outputs of the East San Francisco Bay Research Institute and helps us critically evaluate “AGI research”, distinguishing this from mere predictions.
Next time I’m asked why I focus on AI and not on the “more exciting field of AGI”, I will point them to this essay!
Dear Rodney Brooks, I agree. There is 62 years of AI research now, and deep learning as a technique is maybe not enough to build human level intelligence. But isn’t it so that often these AI researchers worked for decades on things we all intuitively knew will never work? Like doing language understanding by modelling the grammars of languages. Or doing computer vision by modelling detection methods for specific objects and shapes. Shouldn’t we look at it from this perspective: How will AI look like, after 62 years of neural networks research and applying neural networks to real-world problems?
Yes, but! We all had decided that back propagation was a dead end. We were wrong. And for instant, we still don’t know whether grammars for languages may stage a big comeback and overcome many of the problems we see today with the statistical techniques for language translations (see Douglas Hofstadter’s piece in The Atlantic from January: https://www.theatlantic.com/technology/archive/2018/01/the-shallowness-of-google-translate/551570/).
Perhaps 62 years from now CNNs will seem like a quaint idea that held sway over AI for ten or twenty years and then disappeared. Perhaps not. It it was easy to know these things AI would not be so hard.
It is really, really hard.
Recent neuroscience research from Kanter et al at Bar-Ilan University suggests the assumptions of perceptron structures and activation mechanisms from 1950s (Rosenblatt, Hodgkin-Huxley) can be improved upon and that our neurons are more QUANTUM than previously assumed:
* http://neurosciencenews.com/brain-learning-8677/
* https://www.sciencealert.com/physicists-overturn-old-theory-spatial-summation-brain-cells
* https://www.nature.com/articles/s41598-017-18363-1
Wrt Natural Language, John McCarthy made this comment at the Lighthill debate in 1973: “On general purpose robots …in the strong sense … that would exhibit human-quality intelligence, if not quantity, but would be able to deal with a wide variety of situations, the situation is in even worse shape than you think. Namely, even the general formalizations of what the world is like has not been accomplished.
This has turned out to be the difficulty — not the combinatorial explosion.
The common sense programs have occupied relatively little computer time. (They) simply have too limited a formalization. Now, part of this is due to a defect in current systems of mathematical logic — where the systems are designed to be REASONED ABOUT, rather than to be REASONED IN.”
Google Translate, like Google search, is architected to solve the combinatorial explosion problem — not the meaning problem. There are different statistical approaches from Monte Carlo tree search to cosine similarities to co-occurrence big tables that have been applied.
Tellingly, Eric Schmidt said this: “”Let’s say that this group believes Fact A and this group believes Fact B and you passionately disagree with each other and you are all publishing and writing about it and so forth and so on. It is very difficult for us to understand truth,” says Schmidt, referring to the search engine’s algorithmic capabilities.
“So when it gets to a contest of Group A versus Group B — you can imagine what I am talking about — it is difficult for us to sort out which rank, A or B, is higher,” Schmidt says.”
* https://www.cnbc.com/2017/11/21/alphabets-eric-schmidt-why-google-can-have-trouble-ranking-truth.html
In both McCarthy and Schmidt’s comments is the clue that there are some foundational problems with logic itself.
When we examine Aristotle, Descartes, Leibniz and Bayes’ logic frameworks we discover that they are all REASONED ABOUT with no internal model for Reasoned IN.
Moreover, there is an assumption that Reasoning is purely an objective functional logic process whereas in reality human reasoning is a symbiosis of objective+subjective. That subjectivity not being parameterized by probability and statistics because those tools are for frequency distributions and error variance that contain … no directionality and velocity.
Brilliant essay thank you. Vint Cerf noted that the current hype about the applications of AI into most fields really should be termed Artificial Idiot. But we are still far even from achieving that.
So what is the ultimate direction for AI research?
IA(Intelligence Augmentation)? or the replacement of human?
Maybe the vague direction would contribute also to the confusion of AI
I am not at all worried about the vagueness of directions for research. We don’t even know how to ask many of the questions that ultimately looking back will appear to have been brilliant turning points. As with all research (e.g., look at the history of “chemistry”) their is lots of confusion, lots of wrong paths, and lots and lots of work over many centuries. That is the difference between engineering and research. AI is mostly in its research infancy.
Then Can i understand “Research is trying to anything we can possibly, and Engineering is making with consideration to how we can use theorem from research, beneficially to human(e.g. IA – what i said on the comment, human-in-the-loop, enhancing the human work etc)”? Is this the difference with Research and Engineering? I want to know that my thought is right.
That’s a good understanding.
A great essay! I hope journalists take note. Just a tiny factual correction – the first Artificial Life conference was held in 1987 (although the proceedings weren’t published until 1989).
I think the biggest obstacle to AGI is our lack of knowledge about human intelligence (how can you implement a system if you don’t understand its functions?) and a one of the big problems is that there is no “academic community” in place to advance our knowledge.
In spite of the fact that interdisciplinarity is mentioned as a flagship (e.g. even becoming a front page of “Nature”) often it is implemented very superficially (listening to a keynote speech or reading the abstract of a paper). It is not by starting a new journal (e.g. adding “robotics” to “science” in the title) that a new generation of scientists can be formed. On the contrary, it damages the community even more by creating the illusion of being open minded and of bringing a new perspective to the field while this is not the case. Of course GAI (as General Robotics) is very far away in both knowledge and technology and reshuffling the communities is not going to solve the problems by itself but I think it could help to create a new generation of young scientists better equipped to effectively work in team around “intelligence” and redefine the priorities (or find new ones).
This is such a great essay. Thank you for sharing.
I thought I’d share a related essay that you might like by Berkeley professor Michael Jordan -> https://medium.com/@mijordan3/artificial-intelligence-the-revolution-hasnt-happened-yet-5e1d5812e1e7
“We need to realize that the current public dialog on AI — which focuses on a narrow subset of industry and a narrow subset of academia — risks blinding us to the challenges and opportunities that are presented by the full scope of AI, IA and II.”
Thank you again!
Yes, I agree there is a need to stop and question the term ‘AGI’, what it means and whether we are building up towards the hype of achieving human-level intelligence in the next decade or decades. However, one has to acknowledge the pace at which we are witnessing advancement of algorithms, open-source AI platforms, improvements in hardware, and the amount of R&D both government and private which is going into AI today.
Just because we have had no breakthroughs in 60 years, doesn’t mean that the next few decades won’t have them. Its useful to look back at the history of AI to understand its roots, but history isn’t a good indicator of what is coming in the future, especially in terms of technology. One has to only look at image recognition, object recognition, speech recognition to see how AI has made rapid advancements in the last few years. Building on top of these advancements in terms of meta learning, transfer learning, reinforcement learning, adversarial learning etc. is where we are moving the needle. We are now seeing more experimentation and pushing of the boundaries of AI applications more than any time in history. I don’t think the past approaches or organizations mentioned will bring any breakthroughs in AGI. It will most likely be one of the hyperscalars or someone nerdy folks in a garage that will get there. And to think that over the next 10, 20, 30 years we are no likely to be anywhere close to human-level intelligence is another kind of crazy hubris, equivalent to the mad prognostications of AI robots taking over.
Arthur C. Clarke’s fourth law: For every expert there is an equal an opposite expert.
I think you are caught up in the current hype level. You, perhaps, think I am an old fogey (others certainly do).
In my view AI is much harder than chemistry and will take a long time. There was certainly investment in chemistry in order to transmute lead to gold, and that didn’t succeed despite thousands of years of effort. Probably when Dmitri Mendeleev came up with his proto periodic table in 1869 (perhaps analogous in some way to Deep Learning), people thought they were suddenly getting a lot closer.
Oh, and we did have lots of breakthroughs in the past 60 years. If you are not aware of them then you don’t have a deep (in the traditional sense) understanding of AI.
I guess its the ‘old fogey’ vs ‘the shallow and inexperienced so called expert’ 🙂
Don’t get me wrong. I do respect the knowledge, expertise and real-world experience you bring on this topic. I am nowhere qualified in that sense. However, as a rational observer, someone who brings an engineering and technical perspective to this (i.e. acknowledges the limitations of deep learning) someone who constantly questions what he reads and always has a skeptical hat on (being an analyst), I genuinely feel that the fact that the development of AI has been democratized, open-sourced, we as a human beings and problem solving creatures will be tearing down the barriers towards realizing human-level intelligence and gain a better understanding of what that actually means. The path and trajectory to me is very clear. Yes, there will be setbacks and the hype will die down over the next few years, but I don’t see that impacting the long-term trajectory of where we end up, which is closer than we have ever been to replicating human-intelligence in software and hardware.
The bigger question is whether that intelligence will be sentient, conscious, have emotions, feel pain etc. Those to me are very hard problems to solve and we are nowhere close to even understanding what that means for humans. But will we be able to replicate human decision making, perception, judgement, speech, also reasoning and scale that across generalized problem domains – I tend to think feel we are not that far off.
I agree that the long term trajectory will get us there (unless we are not smart enough, see my upcoming blog post). But I still think we are a long way from it. It always seems very close to people just entering the field. And has for 60+ years. And they have all argued that no, now really is the time.
What sort of intelligence can we have that is not sentient. Very useful intelligence perhaps, but it will have no initiative, and will seem very cold and distant to us. We probably won’t respect it, and without respect its roles will be limited in our lives. Which may well be very fine.
Parts of this essay are full of fantastic detail! Wow, actually counting the number of times the word “machine” was used in the paper. I think that really does lead to a better understanding of Turing’s mind at the time. The history is excellent.
But other parts of the essay sound like you got your understanding of neural networks from Doug Hofstadter. Oh, I see; you did. The cavalier dismissal of “deep” is quite telling. It isn’t merely that the newer networks have more layers (they do, and as noted by other commenters, sometimes by more than a few magnitudes). But there is quite a bit of structure in these layers.
Also, the latest advances in AlphaZero are insightful about where we might be heading. It isn’t merely RL, but also a clever merging of GOFAI (in the form of Monte Carlos Tree Search), and deep, structured neural networks. Who would have predicted even 10 years ago that a neural network could learn, from scratch, to play Go and Chess, and continue to learn, becoming the world champion in both games! Looks like probably all games.
I think the history of “connectionism” is equally fascinating and a part of the Origins of AI. No wonder journalists are confused! A reader isn’t even sure that “deep learning” is a part of AI or not.
Gary Marcus’s recent paper “Innateness, AlphaZero, and Artificial Intelligence”, https://arxiv.org/abs/1801.05667, discusses the heavy use of Monte Carlo Tree Search, and other things in AlphaZero. He is pushing back on the hype the RL can do everything. As he points out a lot of knowledge of game playing had to be built in to make it work. And there were lots of championship level Go players on the team. So it is probably disingenuous of those that claim the machine learning could do it all.
[snark]I first studied proofs of convergence in neural networks in 1975, which was fully two years before I first met Douglas Hofstadter. (Which itself was just a few months after I had submitted an admittedly ugly master’s thesis where I proved convergence of machine learning in a modified form of network.) Were you born yet?[/snark]
Nice essay, thanks! Looking forward for the follow-up on research directions 🙂
I think some of the concern about high level machine intelligence could be legitimate, if you consider the scope of changes it would bring to our world. How long would it take to get people ready for and implement UBI? If that is even the right or necessary thing to do for the post AI economy? While things take a long time in AI, they also take a long time in politics.
It is also hard to see the public being happy about research going on in advanced AI development, if there isn’t a sensible sounding idea about how it all might work out in the end. As the AI field gets closer to it’s long term goal that might be another limiting factor.
The whole point of these blog posts is to argue, with reasons, why the predictions about the closeness of high level machine intelligence are way off base.
I guess I am not succeeding at all well in convincing you, though you have not provided any argument whatsoever in your post here. You have just simply asserted exactly what my 100,000 words of these posts argues against. Please read them all before posting here again.
Thank you thank you thank you…as a policy wonk trying repeatedly to communicate to people that AI will not solve government policy delivery issues in anything like the near future, and to do some GD research before buying and regurgitating all the hype, THANK YOU!
She feels warmed for having come in from the cold, however briefly.
>> In my next blog post, hopefully in May of 2018 I will outline all the things we do not understand yet about how to build a full scale artificially intelligent entity.
Well, May 2018 is almost over, now. What happened to that longer essay? :0
As you have guessed it is delayed. Got side tracked by other things. Will get to it in June. For sure!!!!
No pressure 🙂
Dear Dr.Brooks
I am waiting the blog post mentioned below! When can we read the blog post?
And i worry about AI too much.(About will the life of human be meaningless, Will AI be human-centered(it would be related to HCI) forever? Do AI researchers hope automation all tasks? etc…) Am i so sensitive?
———————————————————————————–
In my next blog post, hopefully in May of 2018 I will outline all the things we do not understand yet about how to build a full scale artificially intelligent entity.
My intent of that coming blog post is to:
1. Stop people worrying about imminent super intelligent AI (yet, I know, they will enjoy the guilty tingly feeling thinking about it, and will continue to irrationally hype it up…).
2. To suggest directions of research which can have real impact on the future of AI, and accelerate it.
3. To show just how much fun research remains to be done, and so to encourage people to work on the hard problems, and not just the flashy demos that are hype bait.
———————————————————————————-
Relax! You don’t need to worry about AI.
And I am working on the post. It is what I have spent much of the last week doing. Soon…
Dear Dr. Brooks,
Being “sentient” by definition is “able to perceive or feel things”. Or “responsive to or conscious of sense impressions” Or “finely sensitive in perception or feeling”. It is used in many cases to describe an entity “that is aware it is alive.” There is no mention of intelligence in these definitions.
Now, we speak about Intelligence, given one definition, “the ability to learn or understand or to deal with new or trying situations : reason; also : the skilled use of reason (2) : the ability to apply knowledge to manipulate one’s environment or to think abstractly as measured by objective criteria (such as tests)”
So by definition, aren’t all humans and animals sentient intelligent beings, and therefore an integral part of the evolution of their intelligence is their ability to feel?
My question to you revolves around that fact that you cannot really separate the sentient part from the intelligent part.
It is clear we can create very limited domain AI (not including the sentient part, or at least extremely very little). But, how can we create “artificial general intelligence” if you define this as mimicking human intelligence which itself is a result of combining feelings with evolving intelligence. I totally agree with your recent posts. And I love how you start at the beginning (Turing, MIT, etc.) and run thru the history of academic and other research to try to help people make sense of how hard it is to get to AGI.
So my question (finally), is, shouldn’t all serious AI researchers really frame the AGI discussion around the almost impossible task of creating a machine that can become a true AGI entity. By definition, it seems that you have to create a machine that comes complete with 5 senses, learns, becomes self aware, etc. before you can really call this AGI? Part machine, part organic being. What other better way to convince people of the almost impossible task of and the time involved to understand how to build and get to AGI?
I’ll be trying to take on these issues in an upcoming post in this series.