

I have been working on an upcoming post about megatrends and how they drive tech. I had included the end of Moore’s Law to illustrate how the end of a megatrend might also have a big influence on tech, but that section got away from me, becoming much larger than the sections on each individual current megatrend. So I decided to break it out into a separate post and publish it first. Here it is.
Moore’s Law, concerning what we put on silicon wafers, is over after a solid fifty year run that completely reshaped our world. But that end unleashes lots of new opportunities.
WHERE DID MOORE’S LAW COME FROM?
Moore, Gordon E., Cramming more components onto integrated circuits, Electronics, Vol 32, No. 8, April 19, 1965.
Electronics was a trade journal that published monthly, mostly, from 1930 to 1995. Gordon Moore’s four and a half page contribution in 1965 was perhaps its most influential article ever. That article not only articulated the beginnings, and it was the very beginnings, of a trend, but the existence of that articulation became a goal/law that has run the silicon based circuit industry (which is the basis of every digital device in our world) for fifty years. Moore was a Cal Tech PhD, cofounder in 1957 of Fairchild Semiconductor, and head of its research and development laboratory from 1959. Fairchild had been founded to make transistors from silicon at a time when they were usually made from much slower germanium.
One can find many files on the Web that claim to be copies of the original paper, but I have noticed that some of them have the graphs redrawn and that they are sometimes slightly different from the ones that I have always taken to be the originals. Below I reproduce two figures from the original that as far as I can tell have only been copied from an original paper version of the magazine, with no manual/human cleanup.
The first one that I reproduce here is the money shot for the origin of Moore’s Law. There was however an equally important earlier graph in the paper which was predictive of the future yield over time of functional circuits that could be made from silicon. It had less actual data than this one, and as we’ll see, that is really saying something.
This graph is about the number of components on an integrated circuit. An integrated circuit is made through a process that is like printing. Light is projected onto a thin wafer of silicon in a number of different patterns, while different gases fill the chamber in which it is held. The different gases cause different light activated chemical processes to happen on the surface of the wafer, sometimes depositing some types of material, and sometimes etching material away. With precise masks to pattern the light, and precise control over temperature and duration of exposures, a physical two dimensional electronic circuit can be printed. The circuit has transistors, resistors, and other components. Lots of them might be made on a single wafer at once, just as lots of letters are printed on a single page at one. The yield is how many of those circuits are functional–small alignment or timing errors in production can screw up some of the circuits in any given print. Then the silicon wafer is cut up into pieces, each containing one of the circuits and each is put inside its own plastic package with little “legs” sticking out as the connectors–if you have looked at a circuit board made in the last forty years you have seen it populated with lots of integrated circuits.
The number of components in a single integrated circuit is important. Since the circuit is printed it involves no manual labor, unlike earlier electronics where every single component had to be placed and attached by hand. Now a complex circuit which involves multiple integrated circuits only requires hand construction (later this too was largely automated), to connect up a much smaller number of components. And as long as one has a process which gets good yield, it is constant time to build a single integrated circuit, regardless of how many components are in it. That means less total integrated circuits that need to be connected by hand or machine. So, as Moore’s paper’s title references, cramming more components into a single integrated circuit is a really good idea.
The graph plots the logarithm base two of the number of components in an integrated circuit on the vertical axis against calendar years on the horizontal axis. Every notch upwards on the left doubles the number of components. So while  means
means  components,
components,  means
means  components. That is a thousand fold increase from 1962 to 1972.
components. That is a thousand fold increase from 1962 to 1972.
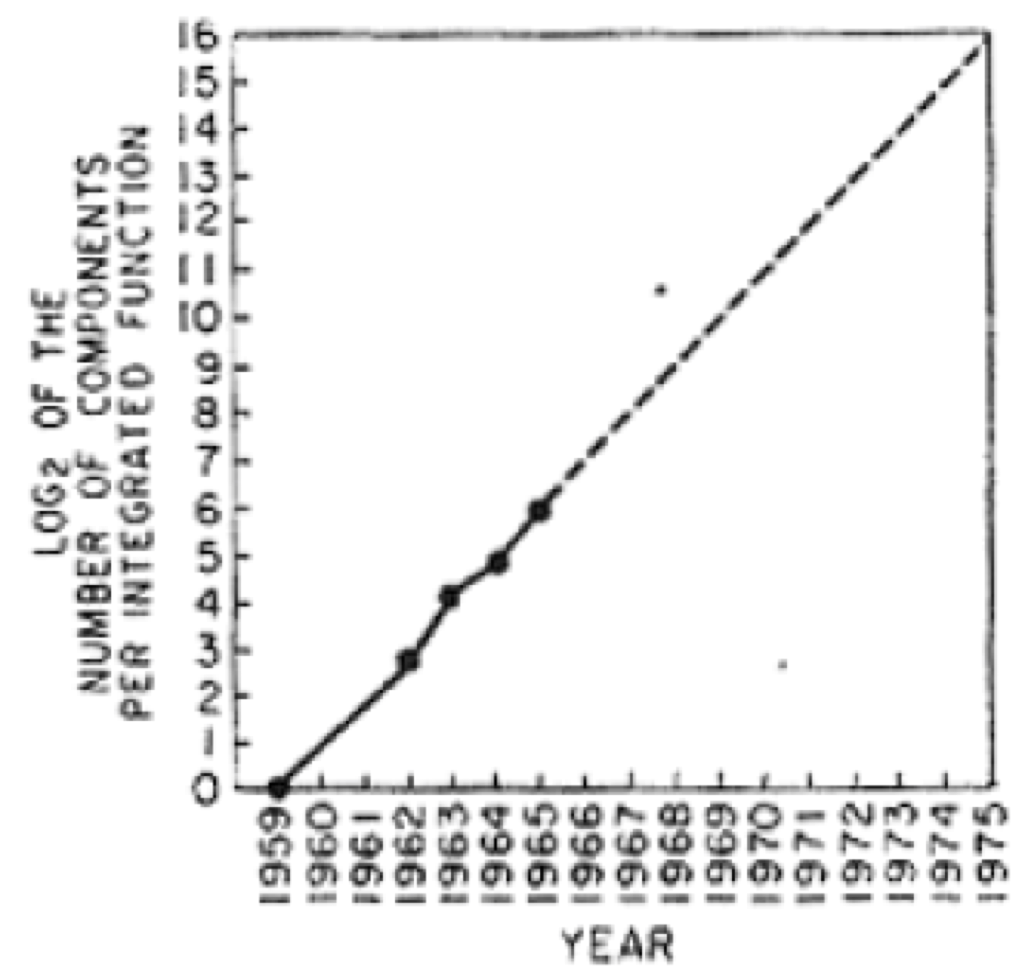
There are two important things to note here.
The first is that he is talking about components on an integrated circuit, not just the number of transistors. Generally there are many more components than transistors, though the ratio did drop over time as different fundamental sorts of transistors were used. But in later years Moore’s Law was often turned into purely a count of transistors.
The other thing is that there are only four real data points here in this graph which he published in 1965. In 1959 the number of components is  , i.e., that is not about an integrated circuit at all, just about single circuit elements–integrated circuits had not yet been invented. So this is a null data point. Then he plots four actual data points, which we assume were taken from what Fairchild could produce, for 1962, 1963, 1964, and 1965, having 8, 16, 32, and 64 components. That is a doubling every year. It is an exponential increase in the true sense of exponential
, i.e., that is not about an integrated circuit at all, just about single circuit elements–integrated circuits had not yet been invented. So this is a null data point. Then he plots four actual data points, which we assume were taken from what Fairchild could produce, for 1962, 1963, 1964, and 1965, having 8, 16, 32, and 64 components. That is a doubling every year. It is an exponential increase in the true sense of exponential .
.
What is the mechanism for this, how can this work? It works because it is in the digital domain, the domain of yes or no, the domain of  or
or  .
.
In the last half page of the four and a half page article Moore explains the limitations of his prediction, saying that for some things, like energy storage, we will not see his predicted trend. Energy takes up a certain number of atoms and their electrons to store a given amount, so you can not just arbitrarily change the number of atoms and still store the same amount of energy. Likewise if you have a half gallon milk container you can not put a gallon of milk in it.
But the fundamental digital abstraction is yes or no. A circuit element in an integrated circuit just needs to know whether a previous element said yes or no, whether there is a voltage or current there or not. In the design phase one decides above how many volts or amps, or whatever, means yes, and below how many means no. And there needs to be a good separation between those numbers, a significant no mans land compared to the maximum and minimum possible. But, the magnitudes do not matter.
I like to think of it like piles of sand. Is there a pile of sand on the table or not? We might have a convention about how big a typical pile of sand is. But we can make it work if we halve the normal size of a pile of sand. We can still answer whether or not there is a pile of sand there using just half as many grains of sand in a pile.
And then we can halve the number again. And the digital abstraction of yes or no still works. And we can halve it again, and it still works. And again, and again, and again.
This is what drives Moore’s Law, which in its original form said that we could expect to double the number of components on an integrated circuit every year for 10 years, from 1965 to 1975. That held up!
Variations of Moore’s Law followed; they were all about doubling, but sometimes doubling different things, and usually with slightly longer time constants for the doubling. The most popular versions were doubling of the number of transistors, doubling of the switching speed of those transistors (so a computer could run twice as fast), doubling of the amount of memory on a single chip, and doubling of the secondary memory of a computer–originally on mechanically spinning disks, but for the last five years in solid state flash memory. And there were many others.
Let’s get back to Moore’s original law for a moment. The components on an integrated circuit are laid out on a two dimensional wafer of silicon. So to double the number of components for the same amount of silicon you need to double the number of components per unit area. That means that the size of a component, in each linear dimension of the wafer needs to go down by a factor of  . In turn, that means that Moore was seeing the linear dimension of each component go down to
. In turn, that means that Moore was seeing the linear dimension of each component go down to  of what it was in a year, year over year.
of what it was in a year, year over year.
But why was it limited to just a measly factor of two per year? Given the pile of sand analogy from above, why not just go to a quarter of the size of a pile of sand each year, or one sixteenth? It gets back to the yield one gets, the number of working integrated circuits, as you reduce the component size (most commonly called feature size). As the feature size gets smaller, the alignment of the projected patterns of light for each step of the process needs to get more accurate. Since  , approximately, it needs to get better by
, approximately, it needs to get better by  as you halve the feature size. And because impurities in the materials that are printed on the circuit, the material from the gasses that are circulating and that are activated by light, the gas needs to get more pure, so that there are fewer bad atoms in each component, now half the area of before. Implicit in Moore’s Law, in its original form, was the idea that we could expect the production equipment to get better by about
as you halve the feature size. And because impurities in the materials that are printed on the circuit, the material from the gasses that are circulating and that are activated by light, the gas needs to get more pure, so that there are fewer bad atoms in each component, now half the area of before. Implicit in Moore’s Law, in its original form, was the idea that we could expect the production equipment to get better by about  per year, for 10 years.
per year, for 10 years.
For various forms of Moore’s Law that came later, the time constant stretched out to 2 years, or even a little longer, for a doubling, but nevertheless the processing equipment has gotten that better time period over time period, again and again.
To see the magic of how this works, let’s just look at 25 doublings. The equipment has to operate with things  times smaller, i.e., roughly 5,793 times smaller. But we can fit
times smaller, i.e., roughly 5,793 times smaller. But we can fit  more components in a single circuit, which is 33,554,432 times more. The accuracy of our equipment has improved 5,793 times, but that has gotten a further acceleration of 5,793 on top of the original 5,793 times due to the linear to area impact. That is where the payoff of Moore’s Law has come from.
more components in a single circuit, which is 33,554,432 times more. The accuracy of our equipment has improved 5,793 times, but that has gotten a further acceleration of 5,793 on top of the original 5,793 times due to the linear to area impact. That is where the payoff of Moore’s Law has come from.
In his original paper Moore only dared project out, and only implicitly, that the equipment would get better every year for ten years. In reality, with somewhat slowing time constants, that has continued to happen for 50 years.
Now it is coming to an end. But not because the accuracy of the equipment needed to give good yields has stopped improving. No. Rather it is because those piles of sand we referred to above have gotten so small that they only contain a single metaphorical grain of sand. We can’t split the minimal quantum of a pile into two any more.
GORDON MOORE’S INCREDIBLE INSIGHT
Perhaps the most remarkable thing is Moore’s foresight into how this would have an incredible impact upon the world. Here is the first sentence of his second paragraph:
Integrated circuits will lead to such wonders as home computers–or at least terminals connected to a central computer–automatic controls for automobiles, and personal portable communications equipment.
This was radical stuff in 1965. So called “mini computers” were still the size of a desk, and to be useful usually had a few peripherals such as tape units, card readers, or printers, that meant they would be hard to fit into a home kitchen of the day, even with the refrigerator, oven, and sink removed. Most people had never seen a computer and even fewer had interacted with one, and those who had, had mostly done it by dropping off a deck of punched cards, and a day later picking up a printout from what the computer had done when humans had fed the cards to the machine.
The electrical systems of cars were unbelievably simple by today’s standards, with perhaps half a dozen on off switches, and simple electromechanical devices to drive the turn indicators, windshield wipers, and the “distributor” which timed the firing of the spark plugs–every single function producing piece of mechanism in auto electronics was big enough to be seen with the naked eye. And personal communications devices were rotary dial phones, one per household, firmly plugged into the wall at all time. Or handwritten letters than needed to be dropped into the mail box.
That sentence quoted above, given when it was made, is to me the bravest and most insightful prediction of technology future that we have ever seen.
By the way, the first computer made from integrated circuits was the guidance computer for the Apollo missions, one in the Command Module, and one in the Lunar Lander. The integrated circuits were made by Fairchild, Gordon Moore’s company. The first version had 4,100 integrated circuits, each implementing a single 3 input NOR gate. The more capable manned flight versions, which first flew in 1968, had only 2,800 integrated circuits, each implementing two 3 input NOR gates. Moore’s Law had its impact on getting to the Moon, even in the Law’s infancy.
A LITTLE ASIDE
In the original magazine article this cartoon appears:

At a fortieth anniversary of Moore’s Law at the Chemical Heritage Foundation in Philadelphia I asked Dr. Moore whether this cartoon had been his idea. He replied that he had nothing to do with it, and it was just there in the magazine in the middle of his article, to his surprise.
in Philadelphia I asked Dr. Moore whether this cartoon had been his idea. He replied that he had nothing to do with it, and it was just there in the magazine in the middle of his article, to his surprise.
Without any evidence at all on this, my guess is that the cartoonist was reacting somewhat skeptically to the sentence quoted above. The cartoon is set in a department store, as back then US department stores often had a “Notions” department, although this was not something of which I have any personal experience as they are long gone (and I first set foot in the US in 1977). It seems that notions is another word for haberdashery, i.e., pins, cotton, ribbons, and generally things used for sewing. As still today, there is also a Cosmetics department. And plop in the middle of them is the Handy Home Computers department, with the salesman holding a computer in his hand.
I am guessing that the cartoonist was making fun of this idea, trying to point out the ridiculousness of it. It all came to pass in only 25 years, including being sold in department stores. Not too far from the cosmetics department. But the notions departments had all disappeared. The cartoonist was right in the short term, but blew it in the slightly longer term .
.
WHAT WAS THE IMPACT OF MOORE’S LAW?
There were many variations on Moore’s Law, not just his original about the number of components on a single chip.
Amongst the many there was a version of the law about how fast circuits could operate, as the smaller the transistors were the faster they could switch on and off. There were versions of the law for how much RAM memory, main memory for running computer programs, there would be and when. And there were versions of the law for how big and fast disk drives, for file storage, would be.
This tangle of versions of Moore’s Law had a big impact on how technology developed. I will discuss three modes of that impact; competition, coordination, and herd mentality in computer design.
Competition
Memory chips are where data and programs are stored as they are run on a computer. Moore’s Law applied to the number of bits of memory that a single chip could store, and a natural rhythm developed of that number of bits going up my a multiple of four on a regular but slightly slowing basis. By jumping over just a doubling, the cost of the silicon foundries could me depreciated over long enough time to keep things profitable (today a silicon foundry is about a $7B capital cost!), and furthermore it made sense to double the number of memory cells in each dimension to keep the designs balanced, again pointing to a step factor of four.
In the very early days of desktop PCs memory chips had  bits. The memory chips were called RAM (Random Access Memory–i.e., any location in memory took equally long to access, there were no slower of faster places), and a chip of this size was called a 16K chip, where K means not exactly 1,000, but instead 1,024 (which is
bits. The memory chips were called RAM (Random Access Memory–i.e., any location in memory took equally long to access, there were no slower of faster places), and a chip of this size was called a 16K chip, where K means not exactly 1,000, but instead 1,024 (which is  ). Many companies produced 16K RAM chips. But they all knew from Moore’s Law when the market would be expecting 64K RAM chips to appear. So they knew what they had to do to not get left behind, and they knew when they had to have samples ready for engineers designing new machines so that just as the machines came out their chips would be ready to be used having been designed in. And they could judge when it was worth getting just a little ahead of the competition at what price. Everyone knew the game (and in fact all came to a consensus agreement on when the Moore’s Law clock should slow down just a little), and they all competed on operational efficiency.
). Many companies produced 16K RAM chips. But they all knew from Moore’s Law when the market would be expecting 64K RAM chips to appear. So they knew what they had to do to not get left behind, and they knew when they had to have samples ready for engineers designing new machines so that just as the machines came out their chips would be ready to be used having been designed in. And they could judge when it was worth getting just a little ahead of the competition at what price. Everyone knew the game (and in fact all came to a consensus agreement on when the Moore’s Law clock should slow down just a little), and they all competed on operational efficiency.
Coordination
Technology Review talks about this in their story on the end of Moore’s Law. If you were the designer of a new computer box for a desktop machine, or any other digital machine for that matter, you could look at when you planned to hit the market and know what amount of RAM memory would take up what board space because you knew how many bits per chip would be available at that time. And you knew how much disk space would be available at what price and what physical volume (disks got smaller and smaller diameters just as they increased the total amount of storage). And you knew how fast the latest processor chip would run. And you knew what resolution display screen would be available at what price. So a couple of years ahead you could put all these numbers together and come up with what options and configurations would make sense by the exact time when you were going to bring your new computer to market.
The company that sold the computers might make one or two of the critical chips for their products but mostly they bought other components from other suppliers. The clockwork certainty of Moore’s Law let them design a new product without having horrible surprises disrupt their flow and plans. This really let the digital revolution proceed. Everything was orderly and predictable so there were fewer blind alleys to follow. We had probably the single most sustained continuous and predictable improvement in any technology over the history of mankind.
Herd mentality in computer design
But with this good came some things that might be viewed negatively (though I’m sure there are some who would argue that they were all unalloyed good). I’ll take up one of these as the third thing to talk about that Moore’s Law had a major impact upon.
A particular form of general purpose computer design had arisen by the time that central processors could be put on a single chip (see the Intel 4004 below), and soon those processors on a chip, microprocessors as they came to be known, supported that general architecture. That architecture is known as the von Neumann architecture.
A distinguishing feature of this architecture is that there is a large RAM memory which holds both instructions and data–made from the RAM chips we talked about above under coordination. The memory is organized into consecutive indexable (or addressable) locations, each containing the same number of binary bits, or digits. The microprocessor itself has a few specialized memory cells, known as registers, and an arithmetic unit that can do additions, multiplications, divisions (more recently), etc. One of those specialized registers is called the program counter (PC), and it holds an address in RAM for the current instruction. The CPU looks at the pattern of bits in that current instruction location and decodes them into what actions it should perform. That might be an action to fetch another location in RAM and put it into one of the specialized registers (this is called a LOAD), or to send the contents the other direction (STORE), or to take the contents of two of the specialized registers feed them to the arithmetic unit, and take their sum from the output of that unit and store it in another of the specialized registers. Then the central processing unit increments its PC and looks at the next consecutive addressable instruction. Some specialized instructions can alter the PC and make the machine go to some other part of the program and this is known as branching. For instance if one of the specialized registers is being used to count down how many elements of an array of consecutive values stored in RAM have been added together, right after the addition instruction there might be an instruction to decrement that counting register, and then branch back earlier in the program to do another LOAD and add if the counting register is still more than zero.
That’s pretty much all there is to most digital computers. The rest is just hacks to make them go faster, while still looking essentially like this model. But note that the RAM is used in two ways by a von Neumann computer–to contain data for a program and to contain the program itself. We’ll come back to this point later.
With all the versions of Moore’s Law firmly operating in support of this basic model it became very hard to break out of it. The human brain certainly doesn’t work that way, so it seems that there could be powerful other ways to organize computation. But trying to change the basic organization was a dangerous thing to do, as the inexorable march of Moore’s Law based existing architecture was going to continue anyway. Trying something new would most probably set things back a few years. So brave big scale experiments like the Lisp Machine or Connection Machine which both grew out of the MIT Artificial Intelligence Lab (and turned into at least three different companies) and Japan’s fifth generation computer project (which played with two unconventional ideas, data flow and logical inference) all failed, as before long the Moore’s Law doubling conventional computers overtook the advanced capabilities of the new machines, and software could better emulate the new ideas.
or Connection Machine which both grew out of the MIT Artificial Intelligence Lab (and turned into at least three different companies) and Japan’s fifth generation computer project (which played with two unconventional ideas, data flow and logical inference) all failed, as before long the Moore’s Law doubling conventional computers overtook the advanced capabilities of the new machines, and software could better emulate the new ideas.
Most computer architects were locked into the conventional organizations of computers that had been around for decades. They competed on changing the coding of the instructions to make execution of programs slightly more efficient per square millimeter of silicon. They competed on strategies to cache copies of larger and larger amounts of RAM memory right on the main processor chip. They competed on how to put multiple processors on a single chip and how to share the cached information from RAM across multiple processor units running at once on a single piece of silicon. And they competed on how to make the hardware more predictive of what future decisions would be in a running program so that they could precompute the right next computations before it was clear whether they would be needed or not. But, they were all locked in to fundamentally the same way of doing computation. Thirty years ago there were dozens of different detailed processor designs, but now they fall into only a small handful of families, the X86, the ARM, and the PowerPC. The X86’s are mostly desktops, laptops, and cloud servers. The ARM is what we find in phones and tablets. And you probably have a PowerPC adjusting all the parameters of your car’s engine.
The one glaring exception to the lock in caused by Moore’s Law is that of Graphical Processing Units, or GPUs. These are different from von Neumann machines. Driven by wanting better video performance for video and graphics, and in particular gaming, the main processor getting better and better under Moore’s Law was just not enough to make real time rendering perform well as the underlying simulations got better and better. In this case a new sort of processor was developed. It was not particularly useful for general purpose computations but it was optimized very well to do additions and multiplications on streams of data which is what is needed to render something graphically on a screen. Here was a case where a new sort of chip got added into the Moore’s Law pool much later than conventional microprocessors, RAM, and disk. The new GPUs did not replace existing processors, but instead got added as partners where graphics rendering was needed. I mention GPUs here because it turns out that they are useful for another type of computation that has become very popular over the last three years, and that is being used as an argument that Moore’s Law is not over. I still think it is and will return to GPUs in the next section.
ARE WE SURE IT IS ENDING?
As I pointed out earlier we can not halve a pile of sand once we are down to piles that are only a single grain of sand. That is where we are now, we have gotten down to just about one grain piles of sand. Gordon Moore’s Law in its classical sense is over. See The Economist from March of last year for a typically thorough, accessible, and thoughtful report.
I earlier talked about the feature size of an integrated circuit and how with every doubling that size is divided by  . By 1971 Gordon Moore was at Intel, and they released their first microprocessor on a single chip, the 4004 with 2,300 transistors on 12 square millimeters of silicon, with a feature size of 10 micrometers, written 10μm. That means that the smallest distinguishable aspect of any component on the chip was
. By 1971 Gordon Moore was at Intel, and they released their first microprocessor on a single chip, the 4004 with 2,300 transistors on 12 square millimeters of silicon, with a feature size of 10 micrometers, written 10μm. That means that the smallest distinguishable aspect of any component on the chip was  th of a millimeter.
th of a millimeter.
Since then the feature size has regularly been reduced by a factor of , or reduced to of its previous size, doubling the number of components in a given area, on a clockwork schedule. The schedule clock has however slowed down. Back in the era of Moore’s original publication the clock period was a year. Now it is a little over 2 years. In the first quarter of 2017 we are expecting to see the first commercial chips in mass market products with a feature size of 10 nanometers, written 10nm. That is 1,000 times smaller than the feature size of 1971, or 20 applications of the rule over 46 years. Sometimes the jump has been a little better than , and so we actually seen 17 jumps from 10μm down to 10nm. You can see them listed in Wikipedia. In 2012 the feature size was 22nm, in 2014 it was 14nm, now in the first quarter of 2017 we are about to see 10nm shipped to end users, and it is expected that we will see 7nm in 2019 or so. There are still active areas of research working on problems that are yet to be solved to make 7nm a reality, but industry is confident that it will happen. There are predictions of 5nm by 2021, but a year ago there was still much uncertainty over whether the engineering problems necessary to do this could be solved and whether they would be economically viable in any case.
Once you get down to 5nm features they are only about 20 silicon atoms wide. If you go much below this the material starts to be dominated by quantum effects and classical physical properties really start to break down. That is what I mean by only one grain of sand left in the pile.
Today’s microprocessors have a few hundred square millimeters of silicon, and 5 to 10 billion transistors. They have a lot of extra circuitry these days to cache RAM, predict branches, etc., all to improve performance. But getting bigger comes with many costs as they get faster too. There is heat to be dissipated from all the energy used in switching so many signals in such a small amount of time, and the time for a signal to travel from one side of the chip to the other, ultimately limited by the speed of light (in reality, in copper it is about  less), starts to be significant. The speed of light is approximately 300,000 kilometers per second, or 300,000,000,000 millimeters per second. So light, or a signal, can travel 30 millimeters (just over an inch, about the size of a very large chip today) in no less than one over 10,000,000,000 seconds, i.e., no less than one ten billionth of a second.
less), starts to be significant. The speed of light is approximately 300,000 kilometers per second, or 300,000,000,000 millimeters per second. So light, or a signal, can travel 30 millimeters (just over an inch, about the size of a very large chip today) in no less than one over 10,000,000,000 seconds, i.e., no less than one ten billionth of a second.
Today’s fastest processors have a clock speed of 8.760GigaHertz, which means by the time the signal is getting to the other side of the chip, the place if came from has moved on to the next thing to do. This makes synchronization across a single microprocessor something of a nightmare, and at best a designer can know ahead of time how late different signals from different parts of the processor will be, and try to design accordingly. So rather than push clock speed further (which is also hard) and rather than make a single microprocessor bigger with more transistors to do more stuff at every clock cycle, for the last few years we have seen large chips go to “multicore”, with two, four, or eight independent microprocessors on a single piece of silicon.
Multicore has preserved the “number of operations done per second” version of Moore’s Law, but at the cost of a simple program not being sped up by that amount–one cannot simply smear a single program across multiple processing units. For a laptop or a smart phone that is trying to do many things at once that doesn’t really matter, as there are usually enough different tasks that need to be done at once, that farming them out to different cores on the same chip leads to pretty full utilization. But that will not hold, except for specialized computations, when the number of cores doubles a few more times. The speed up starts to disappear as silicon is left idle because there just aren’t enough different things to do.
Despite the arguments that I presented a few paragraphs ago about why Moore’s Law is coming to a silicon end, many people argue that it is not, because we are finding ways around those constraints of small numbers of atoms by going to multicore and GPUs. But I think that is changing the definitions too much.
Here is a recent chart that Steve Jurvetson, cofounder of the VC firm DFJ (Draper Fisher Jurvetson), posted on his FaceBook page. He said it is an update of an earlier chart compiled by Ray Kurzweil.
(Draper Fisher Jurvetson), posted on his FaceBook page. He said it is an update of an earlier chart compiled by Ray Kurzweil.
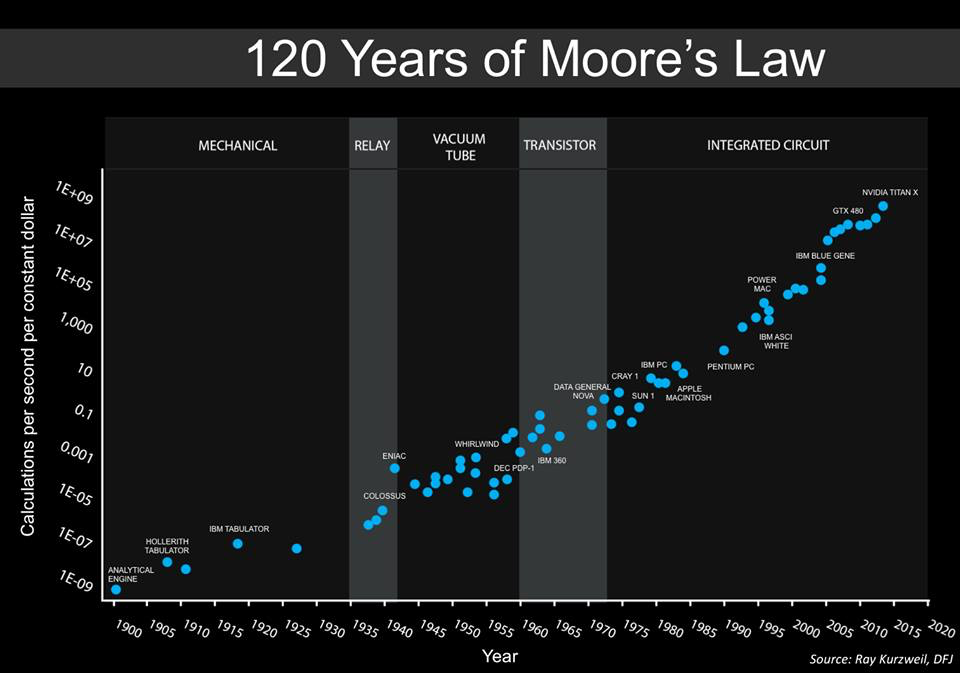
In this case the left axis is a logarithmically scaled count of the number of calculations per second per constant dollar. So this expresses how much cheaper computation has gotten over time. In the 1940’s there are specialized computers, such as the electromagnetic computers built to break codes at Bletchley Park. By the 1950’s they become general purpose, von Neuman style computers and stay that way until the last few points.
The last two points are both GPUs, the GTX 450 and the NVIDIA Titan X. Steve doesn’t label the few points before that, but in every earlier version of a diagram that I can find on the Web (and there are plenty of them), the points beyond 2010 are all multicore. First dual cores, and then quad cores, such as Intel’s quad core i7 (and I am typing these words on a 2.9MHz version of that chip, powering my laptop).
That GPUs are there and that people are excited about them is because besides graphics they happen to be very good at another very fashionable computation. Deep learning, a form of something known originally as back propagation neural networks, has had a big technological impact recently. It is what has made speech recognition so fantastically better in the last three years that Apple’s Siri, Amazon’s Echo, and Google Home are useful and practical programs and devices. It has also made image labeling so much better than what we had five years ago, and there is much experimentation with using networks trained on lots of road scenes as part of situational awareness for self driving cars. For deep learning there is a training phase, usually done in the cloud, on millions of examples. That produces a few million numbers which represent the network that is learned. Then when it is time to recognize a word or label an image that input is fed into a program simulating the network by doing millions of multiplications and additions. Coincidentally GPUs just happen to perfect for the way these networks are structured, and so we can expect more and more of them to be built into our automobiles. Lucky break for GPU manufacturers! While GPUs can do lots of computations they don’t work well on just any problem. But they are great for deep learning networks and those are quickly becoming the flavor of the decade.
While rightly claiming that we continue to see exponential growth as in the chart above, exactly what is being measured has changed. That is a bit of a sleight of hand.
And I think that change will have big implications.
WHAT DOES THE END MEAN?
I think the end of Moore’s Law, as I have defined the end, will bring about a golden new era of computer architecture. No longer will architects need to cower at the relentless improvements that they know others will get due to Moore’s Law. They will be able to take the time to try new ideas out in silicon, now safe in the knowledge that a conventional computer architecture will not be able to do the same thing in just two or four years in software. And the new things they do may not be about speed. They might be about making computation better in other ways.
Machine learning runtime
We are seeing this with GPUs as runtime engines for deep learning networks. But we are also seeing some more specific architectures. For instance, for about a a year Google has had their own chips called TensorFlow Units (or TPUs) that save power for deep learning networks by effectively reducing the number of significant digits that are kept around as neural networks work quite well at low precision. Google has placed many of these chips in the computers in their server farms, or cloud, and are able to use learned networks in various search queries, at higher speed for lower electrical power consumption.
Special purpose silicon
Typical mobile phone chips now have four ARM processor cores on a single piece of silicon, plus some highly optimized special purpose processors on that same piece of silicon. The processors manage data flowing from cameras and optimizing speech quality, and even on some chips there is a special highly optimized processor for detecting human faces. That is used in the camera application, you’ve probably noticed little rectangular boxes around peoples’ faces as you are about to take a photograph, to decide what regions in an image should be most in focus and with the best exposure timing–the faces!
New general purpose approaches
We are already seeing the rise of special purpose architectures for very specific computations. But perhaps we will see more general purpose architectures but with a a different style of computation making a comeback.
Conceivably the dataflow and logic models of the Japanese fifth generation computer project might now be worth exploring again. But as we digitalize the world the cost of bad computer security will threaten our very existence. So perhaps if things work out, the unleashed computer architects can slowly start to dig us out of our current deplorable situation.
Secure computing
We all hear about cyber hackers breaking into computers, often half a world away, or sometimes now in a computer controlling the engine, and soon everything else, of a car as it drives by. How can this happen?
Cyber hackers are creative but many ways that they get into systems are fundamentally through common programming errors in programs built on top of the von Neumann architectures we talked about before.
A common case is exploiting something known as “buffer overrun”. A fixed size piece of memory is reserved to hold, say, the web address that one can type into a browser, or the Google query box. If all programmers wrote very careful code and someone typed in way too many characters those past the limit would not get stored in RAM at all. But all too often a programmer has used a coding trick that is simple, and quick to produce, that does not check for overrun and the typed characters get put into memory way past the end of the buffer, perhaps overwriting some code that the program might jump to later. This relies on the feature of von Neumann architectures that data and programs are stored in the same memory. So, if the hacker chooses some characters whose binary codes correspond to instructions that do something malicious to the computer, say setting up an account for them with a particular password, then later as if by magic the hacker will have a remotely accessible account on the computer, just as many other human and program services may. Programmers shouldn’t oughta make this mistake but history shows that it happens again and again.
Another common way in is that in modern web services sometimes the browser on a lap top, tablet, or smart phone, and the computers in the cloud need to pass really complex things between them. Rather than the programmer having to know in advance all those complex possible things and handle messages for them, it is set up so that one or both sides can pass little bits of source code of programs back and forth and execute them on the other computer. In this way capabilities that were never originally conceived of can start working later on in an existing system without having to update the applications. It is impossible to be sure that a piece of code won’t do certain things, so if the programmer decided to give a fully general capability through this mechanism there is no way for the receiving machine to know ahead of time that the code is safe and won’t do something malicious (this is a generalization of the halting problem — I could go on and on… but I won’t here). So sometimes a cyber hacker can exploit this weakness and send a little bit of malicious code directly to some service that accepts code.
Beyond that cyber hackers are always coming up with new inventive ways in–these have just been two examples to illustrate a couple of ways of how it is currently done.
It is possible to write code that protects against many of these problems, but code writing is still a very human activity, and there are just too many human-created holes that can leak, from too many code writers. One way to combat this is to have extra silicon that hides some of the low level possibilities of a von Neumann architecture from programmers, by only giving the instructions in memory a more limited set of possible actions.
This is not a new idea. Most microprocessors have some version of “protection rings” which let more and more untrusted code only have access to more and more limited areas of memory, even if they try to access it with normal instructions. This idea has been around a long time but it has suffered from not having a standard way to use or implement it, so most software, in an attempt to be able to run on most machines, usually only specifies two or at most three rings of protection. That is a very coarse tool and lets too much through. Perhaps now the idea will be thought about more seriously in an attempt to get better security when just making things faster is no longer practical.
Another idea, that has mostly only been implemented in software, with perhaps one or two exceptions, is called capability based security, through capability based addressing. Programs are not given direct access to regions of memory they need to use, but instead are given unforgeable cryptographically sound reference handles, along with a defined subset of things they are allowed to do with the memory. Hardware architects might now have the time to push through on making this approach completely enforceable, getting it right once in hardware so that mere human programmers pushed to get new software out on a promised release date can not screw things up.
From one point of view the Lisp Machines that I talked about earlier were built on a very specific and limited version of a capability based architecture. Underneath it all, those machines were von Neumann machines, but the instructions they could execute were deliberately limited. Through the use of something called “typed pointers”, at the hardware level, every reference to every piece of memory came with restrictions on what instructions could do with that memory, based on the type encoded in the pointer. And memory could only be referenced by a pointer to the start of a chunk of memory of a fixed size at the time the memory was reserved. So in the buffer overrun case, a buffer for a string of characters would not allow data to be written to or read from beyond the end of it. And instructions could only be referenced from another type of pointer, a code pointer. The hardware kept the general purpose memory partitioned at a very fine grain by the type of pointers granted to it when reserved. And to a first approximation the type of a pointer could never be changed, nor could the actual address in RAM be seen by any instructions that had access to a pointer.
There have been ideas out there for a long time on how to improve security through this use of hardware restrictions on the general purpose von Neumann architecture. I have talked about a few of them here. Now I think we can expect this to become a much more compelling place for hardware architects to spend their time, as security of our computational systems becomes a major achilles heel on the smooth running of our businesses, our lives, and our society.
Quantum computers
Quantum computers are a largely experimental and very expensive at this time technology. With the need to cool them to physics experiment level ultra cold, and the expense that entails, to the confusion over how much speed up they might give over conventional silicon based computers and for what class of problem, they are a large investment, high risk research topic at this time. I won’t go into all the arguments (I haven’t read them all, and frankly I do not have the expertise that would make me confident in any opinion I might form) but Scott Aaronson’s blog on computational complexity and quantum computation is probably the best source for those interested. Claims on speedups either achieved or hoped to be achieved on practical problems range from a factor of 1 to thousands (and I might have that upper bound wrong). In the old days just waiting 10 or 20 years would let Moore’s Law get you there. Instead we have seen well over a decade of sustained investment in a technology that people are still arguing over whether it can ever work. To me this is yet more evidence that the end of Moore’s Law is encouraging new investment and new explorations.
Unimaginable stuff
Even with these various innovations around, triggered by the end of Moore’s Law, the best things we might see may not yet be in the common consciousness. I think the freedom to innovate, without the overhang of Moore’s Law, the freedom to take time to investigate curious corners, may well lead to a new garden of Eden in computational models. Five to ten years from now we may see a completely new form of computer arrangement, in traditional silicon (not quantum), that is doing things and doing them faster than we can today imagine. And with a further thirty years of development those chips might be doing things that would today be indistinguishable from magic, just as today’s smart phone would have seemed like utter magic to 50 year ago me.
FOOTNOTES
Many times the popular press, or people who should know better, refer to something that is increasing a lot as exponential. Something is only truly exponential if there is a constant ratio in size between any two points in time separated by the same amount. Here the ratio is  , for any two points a year apart. The misuse of the term exponential growth is widespread and makes me cranky.
, for any two points a year apart. The misuse of the term exponential growth is widespread and makes me cranky.
Why the Chemical Heritage Foundation for this celebration? Both of Gordon Moore’s degrees (BS and PhD) were in physical chemistry!
For those who read my first blog, once again see Roy Amara‘s Law.
I had been a post-doc at the MIT AI Lab and loved using Lisp Machines there, but when I left and joined the faculty at Stanford in 1983 I realized that the more conventional SUN workstations being developed there and at spin-off company Sun Microsystems would win out in performance very quickly. So I built a software based Lisp system (which I called TAIL (Toy AI Language) in a nod to the naming conventions of most software at the Stanford Artificial Intelligence Lab, e.g., BAIL, FAIL, SAIL, MAIL) that ran on the early Sun workstations, which themselves used completely generic microprocessors. By mid 1984 Richard Gabriel, I, and others had started a company called Lucid in Palo Alto to compete on conventional machines with the Lisp Machine companies. We used my Lisp compiler as a stop gap, but as is often the case with software, that was still the compiler used by Lucid eight years later when it ran on 19 different makes of machines. I had moved back to MIT to join the faculty in late 1984, and eventually became the director of the Artificial Intelligence Lab there (and then CSAIL). But for eight years, while teaching computer science and developing robots by day, I also at night developed and maintained my original compiler as the work horse of Lucid Lisp. Just as the Lisp Machine companies got swept away so too eventually did Lucid. Whereas the Lisp Machine companies got swept away by Moore’s Law, Lucid got swept away as the fashion in computer languages shifted to a winner take all world, for many years, of C.
Full disclosure. DFJ is one of the VC’s who have invested in my company Rethink Robotics.
What do you think about Three dimensional computing?
Hi Ray! Thanks so much for reading this and commenting.
Every time you can add a dimension to something you win super big, so I’m all for 3D computing. Clearly evolution agrees as we see from the vertical columns in out cortex, and the ease of long distance connect in our brains compared to trying to do it on flat silicon. I have not followed it closely but I seem to remember seeing many times over the last few years that various people are trying new technologies to get 3D printed circuits, but not much seems to have come out the other end. It seems very hard even in the abstract due to heat dissipation problems before you get to the technical challenges of keep the structures together as they get taller. Perhaps we will see more serious investment in this now as it does seem like a place to get a whole lot of new bang.
Absolutely. If we can envision 3D chips, we can eventually make it. However, each layer that is added to an IC will present it’s own problems. While I’m not qualified to know what the present factors and tradeoffs for adding layers to 3D IC designs, I would note that each layer only contributes a linear increase in circuit area, now known as “Olsen’s Law” !
Hoped-for quantum speedups have astronomical upper bounds. My back-of-the-envelope estimate for breaking RSA-4096 is 10^{76} cycles on a classical computer, while a quantum computer could do it with millions or billions of operations. But yes, building a scalable quantum computer has not yet been achieved.
As I said, I am not in any way qualified to evaluate quantum computation predictions. But I do see wildly varying predictions which says to me that we don’t yet really know the answers. And the one other thing I know from many years building both hardware and software is that the performance specs before the thing is built are always, always way better than when the thing is actually built and measured…
I know I’m late but…
Quantum computing improvements doesn’t really have upper bounds. If we manage to create a generic purpose quantum computer, it will be something completely different from normal computers (technically: invalidate Turing-Church hypothesis). In other words, quantum computers are able to solve some problems using lower number of operations than classical computers. For example (simplifying slightly), Grover’s algorithm is able to “brute force” all possible N inputs to a function, using only O(sqrt(n)) operations. Using classical computer, if you want to “brute force” check N values, you obviously need to check them all, i.e. O(n) values. It sounds impossible to “brute force” N values with only O(sqrt(n)) operations, but that’s exactly quantum magic for you :>.
So far we don’t know what will be practical in terms of quantum computers that we can actually build. Therefore they sit in the realm of magic at the moment, with unlimited promise. Eventually we will figure them out and then we will start to learn their limitations. They still may be very powerful, but there power will not be infinite.
Interesting, thanks. A golden age sounds good, although we don’t know what we don’t know about the future. Interesting also was the role of Electronics magazine, itself an indirect casualty of Moore’s law. I interned at the magazine in the late ’80s, and some of us moved onto electronic/web journalism from there.
I love that you went back to original sources.
Funny enough, this article showed up in my blog feed while I’ve been thinking about your example of how to sort out a new research direction — a sentence that stuck with me from one of your robotics classes (that fortunately I was forced to take to satisfy an area requirement 🙂 is how you once spent basically a month in your wife’s country (Th?) and worked out your faster,cheaper, out-of-control philosophy. Relative isolation + focus = a lens that let you hit an inflection point and go farther. I’m on my first sabbatical, and weirdly have had a kindred experience, which causes weird remembering of that class 🙂
This isn’t really here-nor-there, but was kind of a odd coincidence.
In any case, keep them coming! There is a vacuum of big picture but technically grounded writing.
Dawson
Great to hear from you Dawson. I looked forward to great things coming form your inflection point!
I’m intrigued by how much efficiency can be gained through SW optimization all up and down the stack. Full disclosure, I was employed by Intel for eight years until last summer. In my time there, I was very impressed by the ingenuity that went into optimization of runtimes, compilers, etc. It seems to me that much of the race for performance will shift into the software space.
Yes, I agree. I almost put a fourth consequence in the post around this point. How sometimes just waiting sped up code enough to not make it worthwhile going back and making things more efficient, but got myself tied up with the word “laziness” which was wrong, so left it out. You have distilled it into crisp words here. Thanks!
Please write more blog posts. I understand that it’s difficult and takes time but please write more. There are only so many people on earth who can boil down complex topics this well.
I saw home computers being sold at KMart and Sears when I visited California in 1982, which was only 17 years after the cartoon in the article.
One very important detail about the Von Neumann architecture is that it allows the use of very different technologies for the processor and the memory. So a processor might use tubes (valves) while the memory uses mercury delay lines or the processor might be built from transistors while the memory uses magnetic cores. Even today the factories that build the processors aren’t quite the same as the ones that produce SDRAMs. I hope to see technology that can both calculate and store in the near future.
I am not a coder, I’m a mechanical engineer. But your essay here is very stimulating, and perhaps has some parallels to the world of steel-and-heat engineering. For example, materials scientists routinely produce new aluminum alloys with _slightly_ better properties, often applicable just to narrow applications, like high-fatigue environments. But the most valuable gains come not from those narrow, cutting-edge gains, but from taking well established materials, and tools, and techniques, and applying them widely. It’s amazing how much clever people can accomplish if you just give them access to steady, reliable, “good-enough” materials.
Some stability–even just a few years worth–on the race up the speed curve for silicon could allow us to consolidate our gains, focusing on highly reliable, highly predictable, well understood, high performance computing systems with a stable and consistent architecture.
Well, maybe that’s too much to hope for, but at least, stuff that isn’t automatically obsolete in two years and vulnerable to attack without patches in two days. Lots of things that could benefit from “smartification” lack it, and lots of “smartification” products aren’t currently reliable enough or safe enough to be used sustainably.
Anyway, that’s the upside I’d love–in my engineer-y conservatism–to see.
On the other hand, I am not convinced your premise is correct.
3D circuits, as the so-famous-I’m-not-totally-sure-that-was-really-him-but-the-site-owner-seems-to-think-so…so-I-guess-it’s-true Ray Kurzweil noted, quantum computers (or just computers that can resist quantum loss of signal for a couple more scale-halvings), low-loss carbon circuits, photonics, and other clever physics tricks could keep the Moore’s Law engine churning, perhaps not in your literalist sense, but by enough definitions to matter. Will that inhibit your future of architecture innovation? If the technical differences are fundamental enough, I would assume some architectural innovation will happen anyway, just to make use of the new tools.
In any event, this was a great essay, a great read, and I think I learned a lot. Thanks for posting it.
I used to be a CMOS ASIC Yield Analyst for HP from 1990-2000. Been out of the business for a long time now, but I think there is great opportunity and promise in the use of Graphene Field Effect Transistors. 3D materials in the form of nano-tubes seem to offer great promise as well. Quantum Computing tied to self assembly nano-materials will I think be the winner. Don’t ask me why I believe this (LOL) – it’s an intergalactic communication channel thing. What a fantastic rigorous article this was.
many thanks for this resouce… useful
Observations:
(1) The end of Moore’s Law is not the end of progress, but only the end of exponential progress for silicon. We are entering the upper end of the S-curve and progress on this technology branch is slowing, but not stopping. Demonstrated 5nm technologies (IBM/TSMC) are likely to be manufacturable, and ~1nm molecular devices have been demonstrated (questionable manufacturability) — maybe that last factor is hard to reach, but doesn’t change the fundamental outlook.
(2) 3D electronics will not be compelling economically if the cost-per-layer is (very roughly) constant, as the cost-per-area (very roughly) was for 2D. That is, the fabrication approach needs to achieve 3D parallelism to have compelling economics (constant cost per volume). Examples are zeolites (aluminum-silicate structures used in petroleum cracking, guided to particular molecular configurations by organic structure-directing agents), and, of course, various biological structures. So we need to learn to orchestrate molecular biology-like processes. The distance in time from one S-curve (silicon) to the next (3D something) is not obviously short (or long).
3D design may have other surprising benefits. A third dimension might aid in the spatial layout of digital circuitry. For example, there are limitations in 2D routing, whereas 3-D routing may provide a means for inter-connection of highly parallel 3-D systolic circuitry. Let’s not forget thee is an opportunity to reduce connection distance as well, leading to faster circuits. Furthermore, my work in RNS has suggested that RNS circuits may benefit from 3D spatial layout.
But here’s my overall take on Moore’s law: IC’s and digital electronics are products of a now mature market relying on Moore’s law, so the death of Moore’s law will change everything radically. I would note that Intel did not predict the most recent shift in the interpretation of Moore’s law. That is, Moore’s law was seen by Intel as “exponentially increasing speed and resources”, but interpreted this mainly as exponentially increasing Operations per second (ops/s). However, the real trend today is operations per second per Watt (ops/sec/Watt). What we really need to focus on is how the slowing of Moore’s law will affect efficiency, not just speed and resources. Intel caught on to this idea somewhat late to the great benefit of ARM, even though Intel invented the embedded controller (and then spun the unit off).
But of course, major processor manufacturers are going to be banking on different optimizations for the needed improvements to fill the gap left by the death of Moore’s law. Examples are multiple cores (Intel core-iX series), highly custom IC’s (Google TPU), more efficient software, and more efficient architecture (ARM).
Radical technologies will be invested in as well. Quantum computers is often cited. I spent a day in a seminar by D-Wave and learned a lot about what their quantum computer can do, and what it can’t do. So right now, while quantum computers can outperform binary computers on some highly specific intractable problems, quantum computers are (currently) not general purpose, and cannot be programmed in a general purpose manner (they are working on that). Quantum computers are not state-machine driven, and they are not deterministic. For example, present quantum computers will provide more than one answer to a given problem.
But other radical new technologies exist, including the one I’ve been working on. I’ve been able to resurrect the concept of operating a computer using a carry-free number system. The carry free number system most often attempted is RNS (residue number system). By un-locking the mechanism for fractional processing in residues, I’ve cracked the problem of general purpose computation in RNS. These systems exhibit radically improved efficiency, and new features not contemplated in the past. But it’s all deterministic, and it’s great strength is in the processing of product summations, the key operation that underlies neural networks and matrix multiplication. You can see more of my work at http://www.digitalsystemresearch.com. Best Regards, Eric.
One more point on the 3D IC discussion:
I was reading John von Neumann’s final essays entitled “Computer and the Brain”, and was fascinated in his comparison of “computer neurons” versus human brain neurons. My guess is that 3 dimensional connections between “neurons” (i.e., synapses) has significant implications; they may be more efficient and more capable than 2 dimensional connections, and more capable than systems which model three dimensional connections using 2 dimensional networks.
In terms of digital circuits, if “digital neurons” need to mirror or simulate biological neurons and their synapses (connectivity), then 3D circuit layout may be a better technological solution ultimately. Eric.
I love this topic, and it will be interesting to see what happens in the market.
IC’s and digital electronics are products of a now mature market, but the death of Moore’s law will change everything radically. But before I go on, let me note that Intel did not predict the most recent shift in the interpretation of Moore’s law. That is, Moore’s law was seen by Intel as “exponentially increasing speed and resources”, but interpreted this as exponentially increasing Operations per second (ops/s). However, the real trend today is operations per second per Watt (ops/sec/watt). What we really need to focus on is how the slowing of Moore’s law will affect efficiency, not just speed and resources. Intel caught on to this idea somewhat late to the great benefit of ARM, even though Intel invented the embedded controller (and then spun the unit off).
But of course, major processor manufacturers are going to be banking on different optimizations for the needed improvements to fill the gap left by the death of Moore’s law. Examples are multiple cores (Intel I-core series), highly custom IC’s (Google TPU), more efficient software, and more efficient architecture (ARM).
Radical technologies will be invested in as well. Quantum computers is often cited. I spent a day in a seminar by D-Wave and learned a lot about what their quantum computer can do, and what it can’t do. So right now, while quantum computers can outperform binary computers on some highly specific intractable problems, quantum computers are (currently) not general purpose, and cannot be programmed in a general purpose manner. Quantum computers are not state driven, and they are not deterministic.
But other radical new technologies exist, including the one I’ve been working on. I’ve been able to resurrect the concept of operating a computer using a carry-free number system. The carry free number system most often attempted is RNS (residue number system). By un-locking the mechanism for fractional processing in residues, I’ve cracked the problem of general purpose computation in RNS. These systems exhibit radically improved efficiency, and new features not contemplated in the past. But it’s all deterministic, and it’s great strength is in the processing of product summations, the key operation that underlies Neural Networks, and matrix multiplication common in scientific processing. See it at digitalsystemresearch.com. Best Regards, Eric.
Why you think the cartoonist make this as a sarcasm ? I think the cartoonist had show the right vision that support Moore’s Idea that the computer will finally be prevalence like any supermarket product and its had finally come true. This is hard to believe in the time where people believe that 10 computers are enough for the whole world, but this cartoon help communicate that.
I think you are wrong, I stand by my wording. I was around then, and know the zeitgeist of the time. We will just have to disagree on how we interpret this 50+ year old cartoon.